ź▐źļź┴ź│źóżĶżĻź▐źļź┴ź╣źņź├ź╔żŪ└Łē”ż“æųż▓ż╩ż¼żķźĘźĻź│ź¾ĀC└čż“║’žō
▒čImagination Technologies╝꿎Ī󊻿╩żżź┴ź├źūĀC└čżŪ└Łē”ż“╣ŌżßĪóDSPź│źóż▐żŪżŌŲŌē┼żĘż┐ź▐źļź┴ź╣źņź├ź╔źūźĒź╗ź├źĄIPź│źóMETAż╬┐ĘźąĪ╝źĖźńź¾ż╬│½╚»ż“Į¬ż©Īóźķźżź╗ź¾ź╣ČĪ═┐īÖŲ░ż“│½╗ŽżĘż┐ĪŻSoCż╦┼ļ║▄ż╣żļż│ż╚ż“┴└żżĪóŠ«żĄż╩ź┴ź├źūĀC└čżŪź▐źļź┴ź│źóż╚Ų▒┼∙ż╬╩┬š`└Łż“Ęeż─IPż╦żĘż┐ż│ż╚ż¼ØŖ─╣żŪżóżļĪŻ65nmźūźĒź╗ź╣żŪ×æļ]ż╣żļż╚700MHzŲ░║ŅżŪ║ŪĮj1552DMIPSż╚żżż”└Łē”ż¼įużķżņżļĪŻ
SoCż╦┼ļ║▄ż╣żļIPź│źóż╚żĘżŲźĘź¾ź░źļź╣źņź├ź╔ź│źóźūźĒź╗ź├źĄż└ż╚ź▀ź╣źęź├ź╚żĘż┐ż╚żŁż╬źņźżźŲź¾źĘż¼─╣ż▒żņżą└Łē”żŽż╚ż┐ż¾ż╦─Ń▓╝ż╣żļż¼Īóź▐źļź┴ź│źóżõź▐źļź┴ź╣źņź├ź╔ż└ż╚źņźżźŲź¾źĘż¼─╣ż»ż½ż½ż├żŲżŌ└Łē”ż╬─Ń▓╝żŽźĘź¾ź░źļź╣źņź├ź╔ź│źóżĶżĻżŌŠ»ż╩żżĪŻźĘź¾ź░źļź╣źņź├ź╔żŪ800MHzŲ░║Ņż╚4ź╣źņź├ź╔żŪ200MHzŲ░║Ņż“╚µż┘żļż╚ĪóźßźŌźĻĪ╝ż╬źņźżźŲź¾źĘż¼ź╝źĒż└ż╚żŌż┴żĒż¾800MHzŲ░║Ņż╬öĄż¼┴ßżżżŌż╬ż╬Īó150źĄźżź»źļĖÕż└ż╚4ź╣źņź├ź╔200MHzŲ░║Ņż╬ż█ż”ż¼╠¾2Ū▄Å]ż»Īó300źĄźżź»źļĖÕż└ż╚3Ū▄Īó500źĄźżź»źļ░╩æųżŪżŽ4Ū▄░╩æųÅ]żżĪŻ
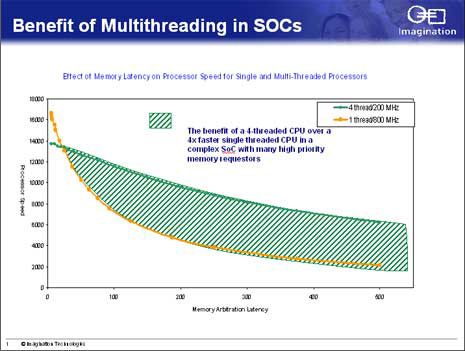
ż│ż╬IPż╬×┤ō■żŽżóż»ż▐żŪżŌSoCżžż╬┴╚ż▀╣■ż▀żŪżóżļż┐żßĪóź▀ź╣źęź├ź╚żŪżŌ└Łē”ż╬═Ņż┴ż╩żżźĻźóźļź┐źżźÓŲ░║Ņż¼▓─ē”ż╩▒■├ōż╦Ė■ż»ĪŻSoC├ō²ŗżŪżŽCPUź│źóż╬ĀC└迎żŪżŁżļż└ż▒žōżķżĘż┐żżĪŻź▐źļź┴ź│źóżŽź│źóż“4Ė─ØŁ═ūż╚ż╣żļż¼Īóź▐źļź┴ź╣źņź├ź╔żŽź│źóż¼1Ė─żŪż╣żÓż┐żßź┴ź├źūĀC└迎Š«żĄż»ż╩żļĪŻ
ź▐źļź┴ź╣źņź├ź╔żŽ4Ė─ż╬źąĪ╝ź┴źŃźļźūźĒź╗ź├źĄż“┼ļ║▄żĘż┐żŌż╬ż╦ŖZż»Īó│░ŗż½żķĖ½żŲżĮżņżŠżņŲ╚╬®żĘż┐Ų░║Ņż¼▓─ē”żŪżóżļĪŻĘQź╣źņź├ź╔żŽRISCź│źóż½DSPż╦ż╩żĻĪóżĮżņżŠżņ╩╠Ī╣ż╬OSżŪŲ░ż»ż│ż╚żŌżŪżŁżļż╚żżż”ĪŻ┴╚ż▀╣■ż▀LinuxżõNucleusĪóImagination╝ęŲ╚śOż╬MeOS źĻźóźļź┐źżźÓOSż╩ż╔ż“ĘQźąĪ╝ź┴źŃźļźūźĒź╗ź├źĄż╦┴╚ż▀╣■żÓż│ż╚ż¼żŪżŁżļĪŻż│ż╬ź▐źļź┴ź╣źņź├ź╔źūźĒź╗ź├źĄ╝┬ĖĮż╬ź½ź«żŽĪóźŽĪ╝ź╔ź”ź©źóź╣ź▒źĖźÕĪ╝źķż╦żóżļĪŻź»źĒź├ź»ż┤ż╚ż╦ź┐ź╣ź»ż“śOŲ░┼¬ż╦┐ČżĻ╩¼ż▒żŲżżżļĪŻ
└Łē”┼¬ż╦żŽźčźżźūźķźżź¾ż╬─╣żĄż“╩čż©żķżņżļżĶż”ż╩Į└Ų└Łż¼żóżĻĪó├▒ĮŃż╩▒ķōQżŽż╣ż░ż╦Į¬ż’żķż╗żļżĶż”ż╦żĘżŲżżżļĪŻż▐ż┐źčźżźūźķźżź¾ż╬├µżŪĪóĘÕæųż▓ź╗Ī╝źų▒ķōQż“ŠW├ōżŪżŁżļż│ż╚żŌ╣ŌÅ]▓Įż╦╣ūĖźżĘżŲżżżļĪŻDSPŗ╩¼żŽĪó1ź»źĒź├ź»żóż┐żĻ16źėź├ź╚MAC▒ķōQż“4Ė─żóżļżżżŽ32źėź├ź╚MAC▒ķōQż“2Ė─╩┬š`ż╦ĮĶ═²żŪżŁżļĪŻ╩Ż╗©ż╩DSP▒ķōQż╦×┤żĘżŲżŽĪó1źĄźżź»źļżóż┐żĻ4ż─ż╬╠┐╬ßż“╚»╣įż╣żļ╗┼┴╚ż▀ż“ŠW├ōżĘżŲVLIW┼¬ż╩╠┐╬ßż“╝┬╣įż╣żļĪŻ
┐ʿʿżMETA2żŽĪóż│żņż▐żŪż╬METAŻ▒ż╬ź│Ī╝ź╔Ė▀┤╣└Łż“Ęeż┴ż╩ż¼żķĪ󟻟Ēź├ź»ż╬╣ŌÅ]▓Įż╦×┤▒■żĘżŲżżżļĪŻż▐ż┐META1żŪżŽ32źėź├ź╚╠┐╬ßż└ż▒ż└ż├ż┐ż¼ĪóMETA2żŪżŽ16źėź├ź╚╠┐╬ßżŌ╝{▓├żĘż┐ĪŻ32źėź├ź╚╠┐╬ßżŽDSPż╦żĶż»╗╚żżĪóCPUż╦żŽ16źėź├ź╚ż“¾H├ōż╣żļż│ż╚żŪĪóARMż╬ThumbźóĪ╝źŁźŲź»ź┴źŃż╬żĶż”ż╦ź│Ī╝ź╔Ė·╬©ż“æųż▓ż┐ĪŻ
ź»źĒź├ź»Å]┼┘żŽĪóźūźĒź╗ź╣ż╦░═┘Tż╣żļĪŻTSMCż╬130nmźūźĒź╗ź╣żŪżŽ360MHzĪó90nmźūźĒź╗ź╣żŪżŽ500MHzżŪŲ░║Ņż╣żļĪŻ─ŃŠ├õJ┼┼╬ü╚Ūż└ż╚ĪóŲ▒▐kźūźĒź╗ź╣żŪ╝■āS┐¶żŽ1/2Ī┴1/3ż╦─Ń▓╝ż╣żļĪŻMETAźóĪ╝źŁźŲź»ź┴źŃżŽ╣ń└«▓─ē”żŪżóżļż┐żßĪóźņźżźóź”ź╚ź─Ī╝źļż“Š}Ų░żŪ─┤┼DżĘż╩ż»żŲżŌ╣Ōżżź»źĒź├ź»Å]┼┘ż“įużķżņżļĪŻż╣żŪż╦źŪźąź├ź░ź─Ī╝źļżŌŲ■Š}żŪżŁżļĪŻ

