NvidiaĪóLSI┐Ę×æēä│½╚»ø]Į╠ż╦░ę╬üż“╚»Ä¦ż╣żļÖ┌└«AIĪųChipNeMoĪūż“Įo│½
╚ŠŲ│öüŪõżĻæųż▓żŪŠå└«─╣żĘżŲżżżļNvidiażŽĪóÖ┌└«AIż“żŽżĖżßż╚ż╣żļAIź│ź¾źįźÕĪ╝źŲźŻź¾ź░ż╬GPUżõźĮźšź╚ź”ź©źóż“żĄż▐żČż▐ż╩▒■├ōż┤ż╚ż╦AIźĮźĻźÕĪ╝źĘźńź¾ż“─¾ČĪżĘżŲżżżļĪŻż│ż╬ż█ż╔LSI└▀╝Ŗ┤³┤ųż“ø]Į╠ż╣żļż┐żßĪóź┴ź├źū└▀╝Ŗż╬ż┐żßż╬Ö┌└«AIżŪżóżļLLMĪ╩Įj(lu©░)æä╠ŽĖ└ĖņźŌźŪźļĪ╦źóźĘź╣ź┐ź¾ź╚ChipNeMoĪ╩┐▐1Ī╦ż“│½╚»ĪóIC×æēä│½╚»ż╦╗╚ż├żŲżżżļż│ż╚ż“ĪųNTTPC GPU Day Ö┌└«AI┤╚ūż╬║ŪØi└■Īūż╬╣ų▒ķżŪĪó£½żķż½ż╦żĘż┐ĪŻ
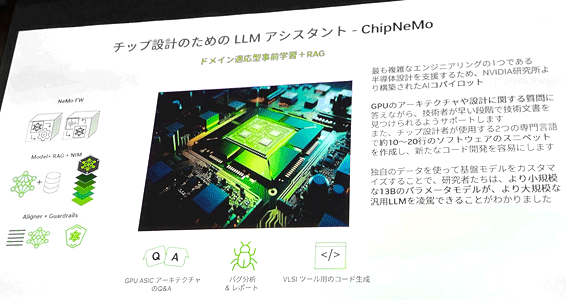
┐▐1ĪĪLSI└▀╝Ŗż╬ż┐żßż╬LLMźóźĘź╣ź┐ź¾ź╚ChipNeMoż“│½╚»ĪĪĮąųZĪ¦Nvidia
NvidiażŽĪó2022ŃQż╦Ö┌└«AIż¼┼ąŠņżĘżŲż»żļż▐żŪĪó2Ī┴3ŃQż╦▐kż─ż╬┐Ę×æēäż“ĮążĘżŲżżż┐ĪŻżĘż½żĘÖ┌└«AIż╬┼ąŠņ░╩═ĶĪóż█ż▄╦ĶŃQ▐kż─┐ʿʿżGPUżõAIź┴ź├źūż“Įąż╣żĶż”ż╦ż╩ż├ż┐ĪŻżĮż╬ŪžĘ╩ż╬▐kż─żŽĪóÖ┌└«AIż“?q©▒)Ö├ōżĘżŲżżżļż│ż╚ż└ż├ż┐ĪŻż┐ż┐ĪóÖ┌└«AIż╚Ė└ż©ż╔żŌĪó▐kż½żķLSI└▀╝Ŗż╬│žØ{ż“ČĄż©╣■żÓż’ż▒żŪżŽż╩żżĪŻAIżŪ║ŪŖZżĶż»╗╚ż’żņżļżĶż”ż╦ż╩ż├ż┐╝{▓├│žØ{ż“╗╚ż”ż╬żŪżóżļĪŻ
LLMżŪżŽĪóĖ└Ėņż“ź╚Ī╝ź»ź¾ż╚Ō}żążņżļ├▒░╠ż╦ČĶ└┌ż├żŲ│žØ{żĄż╗żŲżżżļż¼ĪóżĮż╬ź╚Ī╝ź»ź¾ż╬źčźķźßĪ╝ź┐┐¶ż¼Įj(lu©░)æä╠Žż╦ż╩żņżąż╩żļż█ż╔│žØ{┤³┤ųż¼─╣ż»ż╩ż├ż┐ĪŻ║ŪĮķż╬ź┴źŃź├ź╚GPTżŪżŽ1750▓»źčźķźßĪ╝ź┐ż╚żżż”ĄĮj(lu©░)ż╩źŪĪ╝ź┐ż“│žØ{żĄż╗żļż┐żßż╦┐¶╗hĖ─ż╚żżż”Įj(lu©░)╬╠ż╬GPUż“╗╚ż├żŲżŌ300Ų³µć┼┘ż½ż½ż├ż┐ż╚żĄżņżŲżżżļĪŻżĮż│żŪżŪżŁżļż└ż▒Š»ż╩żżźčźķźßĪ╝ź┐żŪ│žØ{żĄż╗żļöĄ(sh©┤)ż¼╝┬├ō┼¬ż╦ż╩żļĪŻ
LSI└▀╝Ŗż╦żĘżŲżŌżĮż╬ż▐ż▐ź┴źŃź├ź╚GPTż“╗╚ż”ż╬żŪżŽż╩ż»ĪóLSI└▀╝Ŗż╦ØŖ▓ĮżĘż┐żżż’żąź½ź╣ź┐ź▐źżź║żĘż┐Ö┌└«AIż“╗╚ż”öĄ(sh©┤)ż¼żĶżĻ┘ć│╬żŪø]╗■┤ųżŪ±T▓╠ż¼įużķżņżļĪŻNvidiaż¼│½╚»żĘż┐Ö┌└«AIĪųChipNeMoĪūż“╗╚ż©żąĪóGPUż╬źóĪ╝źŁźŲź»ź┴źŃżõ└▀╝Ŗż╦┤žż╣żļä®╠õż╦ż╣ż░┼·ż©żķżņĪóżĘż½żŌØŁ═ūż╩Č\Įč╩ĖĮ±ż“┴ßż»Ė½ż─ż▒żŲż»żņżļĪŻżĄżķż╦LSIż╬└▀╝ŖĖ└Ėņż½żķį~├▒ż╩ź╣ź╦ź┌ź├ź╚Ī╩Ė└Ėņż╬├µż½żķį~├▒ż╦└┌żĻØażĻżĘżŲ║ŲŠW(w©Żng)├ōżŪżŁżļŗ╩¼Ī╦ż“Ö┌└«żĘĪóź│Ī╝ź╔│½╚»ż“į~├▒ż╦żĘżŲżżżļż╚żżż”ĪŻ┤╚ūźŌźŪźļż╚żĘżŲ700▓»źčźķźßĪ╝ź┐ż╬LlamaĪ╩źķź▐Ī╦2ż“╗╚żżż╩ż¼żķĪó130▓»ż¬żĶżė70▓»źčźķźßĪ╝ź┐ż╚Š»ż╩żżChipNeMoź┴źŃź├ź╚źŌźŪźļż¼Įą═Ķż┐ż╚żĘżŲżżżļĪŻ
▐k╚╠ż╦ĪóÖ┌└«AIż╬│žØ{ż╦żŽĪó│žØ{żĄż╗żļż┘żŁźŪĪ╝ź┐ż╬╝²ĮĖż½żķ╗Žż▐żĻĪóźŌźŪźļż╬Ą£Øi│žØ{Īó┤╚ūźŌźŪźļż╦żĶżļ│žØ{Īóź½ź╣ź┐ź▐źżź║ż“ĘążŲĪóźšźĪźżź¾ź┴źÕĪ╝ź╦ź¾ź░żŪĄ£ĖÕ│žØ{ż“żĄż╗żŲż½żķŠW(w©Żng)├ōĪ╩źŪźūźĒźżĪ╦żŪżŁżļżĶż”ż╦ż╩żļĪ╩┐▐2Ī╦ĪŻ
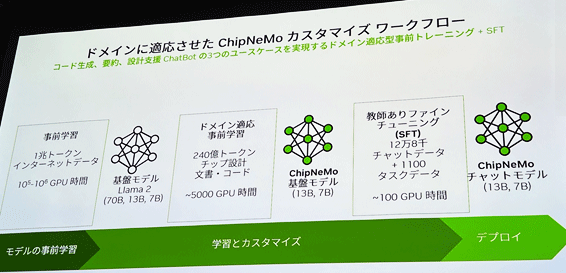
┐▐2ĪĪ╚ŠŲ│öü└▀╝Ŗ├ōż╬Ö┌└«AIźūźķź├ź╚źšź®Ī╝źÓChipNeMoż╬╝{▓├│žØ{ż╦żĶżļŠ}Įńż╬╬ŃĪĪĮąųZĪ¦Nvidia
▐k╚╠ż╬źµĪ╝ź╣ź▒Ī╝ź╣żŪżŽż│żņż└ż▒ż╦ż╚ż╔ż▐żķż║ĪóNVIDIA NeMo GuardrailsżŪ╣ń╦Ī┼¬ż╩ż│ż╚ż“│žØ{żĄż╗żŲżżżļż½ż╔ż”ż½ż“ź┴ź¦ź├ź»ż╣żļĪŻ╝┬║▌ż╦┐õébżĘżŲ╗╚ż”Šņ╣ńż╦żŽ NIMĪ╩NVIDIA Inference MicroserviceĪ╦ż“ŠW(w©Żng)├ōż╣żļż╚Īóż╣żŪż╦╣Į├█żĄżņż┐ź│ź¾źŲź╩ż¼╔Ēō’żĘżŲż¬żĻØŁ═ūż╩źŌźŪźļż“┬ō(li©ón)┘IżĘżŲż╣ż░ż╦╗╚ż©żļżĶż”ż╦ż╩ż├żŲżżżļĪŻ
Nvidiaż╬Ö┌└«AIżŪżŽź│Ī╝ź╔Ö┌└«ż╚═ū╠¾Īó└▀╝Ŗܦ▐qż╬ź┴źŃź├ź╚ź▄ź├ź╚ż╚żżż”3ż─ż╬ĄĪē”ż“╝┬ĖĮżĘżŲżżżļĪŻż│ż”żżż├ż┐╝{▓├│žØ{żŪź½ź╣ź┐ź▐źżź║ż╣żļż┐żßż╬ź─Ī╝źļżŌNvidiażŽ│½╚»żĘżŲż¬żĻĪóRAGĪ╩Retrieval-Augmented GenerationĪ¦ĖĪ║„│╚─źÖ┌└«Ī╦ż╚Ō}żųźŲź»ź╬źĒźĖĪ╝ż¼░ę╬üż“╚»Ä¦ż╣żļĪŻż│ż╬Č\Į迎│░ŗźĮĪ╝ź╣ż½żķŲDįużĘż┐Š╩¾ż“├ōżżżŲĪóÖ┌└« AI źŌźŪźļż╬╗@┼┘ż╚┐«═Ļ└Łż“Ė■æųżĄż╗żļżŌż╬ż└ż╚żżż”ĪŻ
NVIDIA NeMo żŽĪóź½ź╣ź┐ź▐źżź║żĄżņż┐ź©ź¾ź┐Ī╝źūźķźżź║ ź░źņĪ╝ź╔ż╬Ö┌└« AI źŌźŪźļż╬╣Į├█ż╦ØŖ▓ĮżĘż┐Īóź¬Ī╝źūź¾źĮĪ╝ź╣ż╬ź©ź¾ź╔ź─Ī╝ź©ź¾ź╔ źūźķź├ź╚źšź®Ī╝źÓżŪżóżļĪŻLSI└▀╝Ŗż└ż▒żŪżŽż╩ż»Īó┴Ž╠¶│½╚»żõźŪĪ╝ź┐╩¼└ŽĪóźĘź▀źÕźņĪ╝źĘźńź¾ĪóźĒź▄źŲźŻź├ź»ź╣żõźŪźĖź┐źļź─źżź¾ż╩ż╔══Ī╣ż╩AIź│ź¾źįźÕĪ╝źŲźŻź¾ź░źūźķź├ź╚źšź®Ī╝źÓż╦żĄż▐żČż▐ż╩NeMoźūźķź├ź╚źšź®Ī╝źÓż¼żóżļĪŻ

