Nvidiaż╬║Ū┐Ęź┴ź├źūGH200ż╦ż╩ż╝CPUż╚GPUż“ĮĖ└čż╣żļż╬ż½
Nvidiaż¼Computex TaipeiżŪÖ┌└«AIĖ■ż▒ż╬║Ū┐Ęź┴ź├źūGH200Ī╩┐▐1Ī╦ż“╚»╔ĮżĘĪóżĮżņż“ĪųGrace HopperĪūż╚ć@¤²ż▒ż┐ĪŻGraceżŽCPUŗ╩¼ĪóHopperżŽGPUŗ╩¼ż“╗žżĘżŲżżżļĪŻ╝┬żŽżĮż╬Øiż╦AMDżŌMI300Xż╚żżż”Ö┌└«AIĖ■ż▒ż╬GPUź┴ź├źūż“╚»╔ĮżĘżŲżżżļż¼Īóż│ż│żŪżŌCPUż╚GPUż“┴╚ż▀╣ńż’ż╗żŲ╗╚ż”ĪŻż╩ż╝ż½ĪŻ

┐▐1ĪĪNvidiaż╬CPUż╚GPUż“ĮĖ└čżĘż┐GH200ĪĪĮąųZĪ¦Nvidia
Grace Hopperż└ż▒żŪżŽż╩ż»ĪóAMDż╬MI300źĘźĻĪ╝ź║żŪ║ŪĮķż╦CES 2023żŪ╚»╔ĮżĘż┐MI300AżŌCPU+GPUż╬AIź┴ź├źūżŪżóż├ż┐ĪŻAMDżŽÖ┌└«AIĖ■ż▒ż╬AIź┴ź├źū╣Į└«ż“ż│ż╬║óż½żķżĘż├ż½żĻż╚╣═ż©żŲżżż┐£Iż¼żóżļĪŻ5ĘŅ23Ų³ż╦żŽ┼┼╬üĖ·╬©ż╬╬╔żżź╣źčź│ź¾Top500ż╦║▄ż├żŲżżżļæų░╠10╝ęż╬ŲŌ7╝ęż¼AMDż╬EPYC CPUż╚Instinct MI250 AIźóź»ź╗źķźņĪ╝ź┐ż“╗╚ż├żŲżżżļż╚╚»╔ĮżĘż┐ĪŻAMDż¼ź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐żõż│żņż½żķż╬HPCĪ╩High Performance ComputingĪ╦ĪóAIź╣Ī╝źčź¾ź│ź¾źįźÕĪ╝ź┐ż╩ż╔ż╦CPU+GPUż╬ź╗ź├ź╚ż“╗╚ż├żŲżżż»╣Įż©ż“Ė½ż╗żŲżżżļĪŻ
8ĘŅż╦AMDż¼ Instinct MI300Xż“╚»╔ĮżĘż┐ż╚żŁżŽGPUż“ĮjżŁż»żĘż┐AIźóź»ź╗źķźņĪ╝ź┐ż╬ź┴ź├źūż└ż├ż┐ż¼Īó6ĘŅ13Ų³ż╦żŽŗī4└ż┬Õż╬EPYCż╚żżż”CPUż“╚»╔ĮżĘżŲż¬żĻĪóAIźĘź╣źŲźÓż╦żŽCPU+GPUż╬ź╗ź├ź╚ż¼Ö┌żŁżŲż»żļż╚Įęż┘żŲżżżļĪŻż▐ż┐MI300żŽĪóź┴ź├źūźņź├ź╚ż“īÖ├ōżĘżŲźčź├ź▒Ī╝źĖź¾ź░żĘż┐║ŪĮķż╬GPU×æēäżŪżóżĻĪóAMDżŽ└Ķ├╝źčź├ź▒Ī╝źĖČ\Įčż“┐õżĘ┐╩żßżŲżżż»ĪŻ
GH200żŽĪó┐▐2ż╦┐āżĄżņżļżĶż”ż╦Īó║ĖŖõż╬CPUż╚īÜŖõż╬GPUż“ż”ż▐ż»╗╚żż╩¼ż▒żļż│ż╚ż╦żĶż├żŲĪóĖ·╬©żĶż»▒ķōQżŪżŁżļżĶż”ż╦żĘżŲżżżļĪŻ
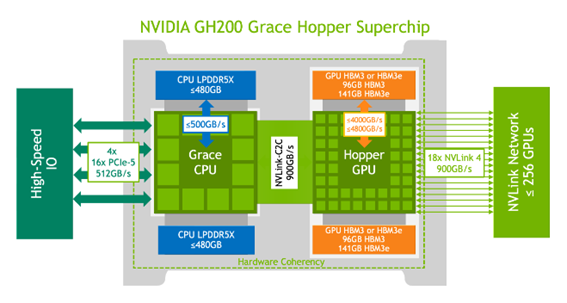
┐▐2ĪĪGH200ż╬ŲŌŗźųźĒź├ź»┐▐ĪĪĮąųZĪ¦Nvidia Grace Hopper Superchip Architectureź█ź’źżź╚ź┌Ī╝źčĪ╝
æųż╬┐▐żŪżŽĪóCPUż╬źßźŌźĻż╚żĘżŲLPDDR5Xż“ĪóGPUż╦żŽHBM3Eż“╗╚ż”ĪŻCPUż╚GPUż“900GB/sż╚żżż”«Ć╣ŌÅ]ż╬NVLinkżŪż─ż╩ż«Īó│░ŗż╬GPUż╚żŌNVLinkżŪ└▄¶öżĘ│╚─ź└Łż“│╬╩▌ż╣żļĪŻ
NvidiażŽCPUż╚żĘżŲŲ╚śO╗┼══ż╬Graceż“╗╚ż”Ė·▓╠ż“Īóx86 CPUż╚ż╬╚µ│ėżŪ└Ō£½żĘżŲżżżļĪŻCPUźßźŌźĻż╬źąź¾ź╔╔²żŽĪóx86ÅUż╬150GB/sż╦×┤żĘżŲ3Ū▄░╩æųż╬500GB/sż╚ż╩żĻĪóCPUż╚GPU┤ųż╬żõżĻŲDżĻ├ōż╬źŪĪ╝ź┐╔²żŽx86ÅUż╬128GB/sż╦×┤żĘżŲNVLink-C2Cż“╗╚żż900GB/sĪóż╚Ų╚śO╗┼══ż╬CPUżŪźąź¾ź╔╔²ż“╣Łż▓żļż│ż╚ż¼żŪżŁż┐ĪŻżĄżķż╦┬Šż╬GH200ż╚żŌ└▄¶öżĘżŲźĘź╣źŲźÓż“│╚─źż╣żļŠņ╣ńżŌNVLinkż“╗╚ż├żŲ└▄¶öż╣żļĪŻ
żĄżķż╦źßźŌźĻż“CPUż╚GPUżŪČ”Ń~żŪżŁżļżĶż”ż╦╣®╔ūżĘżŲżżżļĪŻżĮż╬ż┐żßż╦ر═²źßźŌźĻż╦─Š└▄ż─ż╩ż░ż╬żŪżŽż╩ż»ĪóźßźŌźĻż╬╩č┤╣źŲĪ╝źųźļż“║ŅżĻĪóż│ż│ż“▓żĘżŲĄŁ▓▒żĄż╗żļر═²źßźŌźĻĪ╩HBMżõLPDDR5xĪ╦ź┌Ī╝źĖż╦╚¶żųżĶż”ż╦żĘż┐ĪŻCPUż╚GPUżŽ┤░µ£ż╦Ų▒żĖźßźŌźĻź╗źļż╦źóź»ź╗ź╣żŪżŁżļĪŻ
AIż╬▒ķōQĮĶ═²ż╦GPUż└ż▒żŪżŽż╩ż»CPUżŌŠW├ōż╣żļż╦żŽŚlż¼żóżļĪŻż│ż╬Šņ╣ńCPUżŽöUĖµż└ż▒żŪżŽż╩ż»▒ķōQĄĪē”żŌ’Lż½ż╗ż╩żżż┐żßĪó║ŪĮj128źėź├ź╚ż▐żŪ│╚─źżŪżŁżļźŽźżź©ź¾ź╔ż╬Arm CPUź│źóżŪżóżļArm Neoverse V2 CPUź│źóż“72Ė─╗╚ż├żŲżżżļĪŻ
▐k╚╠ż╦żŽĪóGPUż╦żŽĮj╬╠ż╬└čŽ┬▒ķōQ▀_ż╚źßźŌźĻż¼ĮĖ└迥żņżŲż¬żĻĪó▒ķōQż└ż▒ż╦└ņŪ░ż╣żļGPUżŪ╣įš`▒ķōQż“╣įż”ż│ż╚ż¼¾HżżĪŻØŖż╦└čŽ┬▒ķōQ▀_ż“Įj╬╠ż╦ĮĖ└čżĘżŲżżżļGPUżŽĪó╠®ż╩╣įš`▒ķōQż╦żŽ┼¼żĘżŲżżżļĪŻ
żĘż½żĘĪóšÅż╬▒ķōQżŪżŽźņźżźŲź¾źĘż╦╗■┤ųż¼ż½ż½żĻż╣ż«GPUżŽ┼¼żĄż╩żżĪŻź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪżŽĪó─_ż▀żõźŪĪ╝ź┐Ī▀0=0ż╬╝ŖōQż¼╝┬ż╦¾HżżĪŻż│żņż“GPUżŪ╣įš`╝ŖōQż╣żļż│ż╚żŽ±T▓╠ż¼ź╝źĒż╚żżż”╠ĄŠGż“╝ŖōQż╣żļż│ż╚ż╦ż╩żļĪŻ╠ĄŠGż╩╝ŖōQż“żĘż╩ż»żŲ║čżÓżĶż”ż╦šÅż╬╣įš`▒ķōQżŪżŽCPUżŪ×┤▒■ż╣żļĪŻż│żņż½żķ╗■┤ųż╬ż½ż½żļÖ┌└«AIż╬│žØ{ż╦żŽĪó╠ĄŠGż╩ż»ĮĶ═²╗■┤ųż“ø]ż»ż╣żļż┐żßż╦ĪóCPUż╚GPUż“ź╗ź├ź╚żŪ╗╚ż”ż│ż╚ż¼’Lż½ż╗ż╩ż»ż╩żļż└żĒż”ĪŻ
╗▓╣═½@╬┴
1. "NVIDIA Grace CPU Superchip Whitepaper", Nvidia Whitepaper

