ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(4-3)
ź╦źÕĪ╝źĒź┴ź├źūż╬┬Õ╔Į╬Ńż╚żĘżŲĪóĪ╩4-3Ī╦żŪżŽ░ĄĮ╠Č\Įčż“├ōżżż┐ź┴ź├źūż╬│½╚»╬Ńż╚żĘżŲĪóGoogleż¼│½╚»żĘż┐ź╦źÕĪ╝źĒź┴ź├źūTPUĪ╩Tensor Processing UnitĪ╦Ī󿬿ĶżėStanfordĮj(lu©░)│žż“├µ┐┤ż╦Ė”ē|żĄżņżŲżżżļ░ĄĮ╠Č\ĮčDeep Compressionż“Šę▓ż╣żļĪŻ░ĄĮ╠żŽĪó╬╠╗ę▓Įźėź├ź╚┐¶ż“32źėź├ź╚ż╩ż╔ż½żķ16źėź├ź╚żóżļżŽ8źėź├ź╚ż╦║’žōż╣żļČ\ĮčżŪĪóź╦źÕĪ╝źĒź┴ź├źūż╬┼┼╬üĖ·╬©ż“æųż▓żļżŌż╬ĪŻŠ»Ī╣─╣żżż¼Īóź┴ź├źū▓Įż╦żŽØŁ═ūż╩Č\ĮčżŪżóżļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
4.3ĪĪ┬Õ╔Į┼¬ź┴ź├źūĪ╩░ĄĮ╠Č\Įčż“├ōżżż┐ź┴ź├źūĪ╦Ī┴šÅ░ĄĮ╠Īó╬╠╗ę▓ĮżĮżĘżŲźĒź╣źņź╣
╦▄£IżŪ░Ęż”źŪĪ╝ź┐ż¬żĶżė─_ż▀ż╬░ĄĮ╠Č\Į迎╝┬╣į├ōż└ĪŻČ”─╠ż╬Ū¦╝▒żŽĪų│žØ{╗■ż╦żŽĖĒ║╣Ąš┼┴ś“╦Īż╬─_ż▀ż“╚∙─┤ż╣żļ║▌ż╦╗@┼┘ż“═ūżĘ¾Hźėź├ź╚ż¼ØŁ═ūĪūż╚żżż”┼└ż└ĪŻ╗@┼┘╬¶▓Įż╦┤žżĘżŲżŌŠ«żĄżßżŪ0.5%µć┼┘ż▐żŪżŪżóżļĪ╩ż│ż╬ß×═ŲšJ░ŽżŽ┼¼├ōż╬źóźūźĻż╬╗┼══ż╦Įj(lu©░)żŁż»░═┘Tż╣żļżŽż║Ī╦ĪŻ
╦▄£Iż╬(1)żŪGoogle╝ęż╬ASICżŪżóżļTPUż╦┤žŽóż╣żļČ\Įčż“Īó(2)ż╚(3)żŪStanfordĮj(lu©░)│žż“├µ┐┤ż╚żĘż┐Deep Compressionż╦┤žż╣żļ▐kŽóż╬Č\Įčż“└Ō£½ż╣żļĪŻż╩ż¬ØiŪvżŽźŪĪ╝ź┐ź╗ź¾ź┐ż½żķźŌźąźżźļżŽżŌż╚żĶżĻIoT (ź©ź├źĖ)ż▐żŪż╬·t│½ż“┴└żżĪóĖÕŪvżŽźŌźąźżźļĪ╩ź©ź├źĖĪ╦×┤▒■ż╬ē|Č╦Ī╩?!Ī╦ż“┴└ż├żŲżżżļĪŻżĮżĘżŲĪó║ŪĖÕż╦(4)żŪ┬Šż╬ź┴ź├źūĪ╩IoE┼∙Ī¦4.1£IżŪ└Ō£½Ī╦ż╬░ĄĮ╠Č\ĮčżŌ┤▐żßżŲµ£öüż“▄ććĶż╣żļĪŻż╩ż¬Īó░ĄĮ╠Č\Įčż╦żŽBinary Connect/Binarized Neural Networkż╚żżż├ż┐źąźżź╩źĻżŪż╬│žØ{Ī”╝┬╣įĮĶ═²ż“├ĄĄßż╣żļŲ░Ė■żŌżóżļż¼Īó╦▄┤¾ąMżŪżŽ│õ░”żĘż┐ĪŻż▐ż┐TPUż╦┤žżĘżŲżŽĪó2017ŃQ4ĘŅż╦GoogleżĶżĻTPUż╦┤žżĘżŲż╬Š▄║┘ż╩Šę▓ĪóĄ┌żėéb╩Ėż¼Įąż┐ż╬żŪżĮż┴żķż“╗▓Š╚żĘżŲż█żĘżżĪŻ░╩▓╝ż╬źųźĒź░żĶżĻéb╩Ėż╬ź└ź”ź¾źĒĪ╝ź╔ż¼▓─ē”Ī╩https://cloudplatform.googleblog.com/2017/04/quantifying-the-performance-of-the-TPU-our-first-machine-learning-chip.htmlĪ╦ĪŻ
┐▐35żŽż│ż│1ŃQżŪż╬Googleż╚StanfordĮj(lu©░)│žż“├µ┐┤ż╚żĘż┐2ż─ż╬Ų░żŁż“╗■ÅUš`żŪż▐ż╚żßż┐żŌż╬ż└ĪŻ░ĄĮ╠ĮĶ═²ż╬öĄ(sh©┤)╦Īż½żķLSI╝┬äóĪ╩GoogleżŽASICż“│½╚»Ī”╗╚├ō├µĪ╦Īó╝┬▒■├ōżžż╚ŠåŚ„ż╦·t│½żĘżŲżżżļż╬ż¼Ė½żŲŲDżņżļĪŻØŖż╦ØŖ─¦┼¬ż╩ż╬żŽĪóNMTĪ╩Neural Machine TranslationĪ¦RNNź┘Ī╝ź╣ż╬ź╦źÕĪ╝źķźļĄĪ│Ż╦▌ŚlĪ╦ż“║Y┼¬ż╚żĘżŲĖ”ē|Ī”│½╚»ż¼ŠåżŪżóżļ┼└ż└ĪŻµ£±T╣ń┴žż“╝ńöüż╚żĘżŲ┐¶╝åźßź¼źąźżź╚Ī╩1ź«ź¼Ī╦Ąķż╬źĄźżź║ż╬ź═ź├ź╚ź’Ī╝ź»źŌźŪźļżŪżóżļĪŻŖZżżĮø(j©®ng)═ĶĪóź╣ź▐ź█żŪśOŲ░╦▌Ślż¼ź╣ź┐ź¾ź╔źóźĒĪ╝ź¾żŪżŪżŁżļżĶż”ż╦ż╩żļ└¬żżż└ĪŻŲ³╦▄Ėņż“ź╣ź▐ź█ż╦ÅBżĘż½ż▒żļż╚Īóź╣ź▐ź█ż¼├µ╣±Ėņż“żĘżŃż┘ż├żŲż»żņżļż╬żŌ┤ųŖZż½żŌżĘżņż╩żżĪŻ
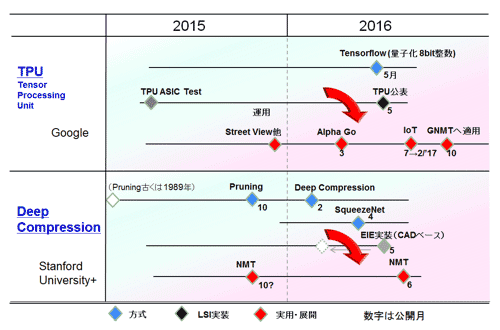
┐▐35 ░ĄĮ╠Č\Įčż╬│½╚»ż╬2ż─ż╬╬«żņĪ╩┴└ż”żŽźŌźąźżźļ/ź©ź├źĖ▒■├ōĪ╦
(1)TPU (Tensor Processing Unit)ĪĪGoogle╝ęĪ┴źŪĪ╝ź┐ź╗ź¾ź┐ż½żķź©ź├źĖżž
┐▐35ż╦┐āż╣żĶż”ż╦ĪóTPUżŽĪó2016ŃQ5ĘŅ18Ų³ż╦Googleż╬źųźĒź░żŪ╚»╔ĮĪ╩╗▓╣═½@╬┴94Īó95Ī╦żĄżņż┐ĪŻ2014ŃQ╦▄│╩│½╚»ŠÆŠ}Īó2015ŃQĮšż╦żŽź┴ź├źūż“ĪóżĮżĘżŲ22Ų³żŪ╝┬Ė·┼¬ż╦╗╚ż©żļżĶż”ż╦ż╩ż├ż┐ż╚ż╬ż│ż╚ż└ĪŻźŪĪ╝ź┐źĄĪ╝źążŪ╗╚ż’żņżļ╝┬╣į├ōż╬└ņ├ōASICź┴ź├źūżŪżóżļĪŻ╝┬║▌ż╦RankBrain/Street View/Alpha Go┼∙ż╦╗╚├ōżĄżņż┐ż╚ż╬ż│ż╚ż└Ī╩┐▐36Ī╦ĪŻ
Alpha Goż╦╗╚├ōżĄżņż┐żżż’żµżļ┐═╣®ē¶ē”ż¼īÜż╬źķź├ź»ż└ĪŻGoogleż╬Tensorflowż╬źķźżźųźķźĻæųżŪŲ░ż»ż│ż╚ż¼Øi─¾żŪżóżļĪŻŲŌŗżŽźŪĪ╝ź┐Ī”─_ż▀Č”ż╦8źėź├ź╚żŪ▒ķōQĪóź©ź═źļź«Ī╝Ė·╬©ż¼1ĘÕĪ╩10Ū▄Ī╦▓■║¤żĄżņż┐ĪŻźŽĪ╝ź╔ź”ź¦źóż╬Š▄║┘żŽ╔į£½ż└ĪŻ32źėź├ź╚╔ŌŲ░Š«┐¶┼└▒ķōQż“Īó8źėź├ź╚żŪ▒ķōQżĘżŲżżżļż╩żķ▒ķōQöv┐¶ż¼1/4ż╦žōŠ»Ī╩Å]┼┘Ī╦Īó1▒ķōQ┼÷ż┐żĻż╬źßźŌźĻźóź»ź╗ź╣╔ķ▓┘ż¼1/4ż╦║’žōż╣żļĄ£ż½żķź©ź═źļź«Ī╝Ė·╬©ż¼10Ū▄µć┼┘Ė■æųż╣żļĪŻĪ╩æųĮęż╬éb╩ĖżŪżŽĪó┴Ļ×┤╚µ│ėż└ż¼×┤CPU/GPUż╬Å]┼┘╚µ15Ī┴30Ū▄Īóź©ź═źļź«Ī╝Ė·╬©30Ī┴80Ū▄ż╚╩¾╣żĄżņżŲżżżļĪ╦ĪŻż╩ż¬ĪóŲ■Įą╬üŗ╩¼żŽ32źėź├ź╚╔ŌŲ░Š«┐¶┼└ż╬ż▐ż▐░Ęż©żļż╬ż¼ź▌źżź¾ź╚żŪżóżļĪŻ

┐▐36 TPUż¼╝┬ä󿥿ņż┐ź▄Ī╝ź╔Ī╩║ĖĪ╦ĪóźŪĪ╝ź┐ź╗ź¾ź┐żŪż╬╝┬╣įėXČĘĪ╩źķź├ź»ż╦┼ļ║▄Ī¦īÜ┐▐Ī╦ĪĪAlpha GożŪ╗╚├ōżĄżņż┐źĄĪ╝źąźķź├ź»Ī╩°Ø╚ūż╬│©ż¼ØażĻ¤²ż▒żķżņżŲżżżļĪ╦
Ī╩└^┐┐żŽ╗▓╣═½@╬┴94 Google Cloud Platform BlogżĶżĻ┼Š║▄Ī╦
GoogleźµĪ╝źČĪ╝ż╬AI╗╚├ō╬╠Ī╩╝┬╣įĪ╦ż╬╗ž┐¶┤ž┐¶┼¬ż╩äPżėżžż╬×┤Ń^║÷ż╚Ė½żŲż╚żņżļĪ╩3Ī┴4Ū▄ż╬źµĪ╝źČĪ╝ż“┴ĻŠ}ż╦żŪżŁżļĪ╦ĪŻż▐ż┐źčź’Ī╝─Ńžōż╦żĶżļźŪĪ╝ź┐ź╗ź¾ź┐ż╬░▌Ęeź│ź╣ź╚─Ńžōż╦żŌĘęż¼żļĪ╩źßźżź¾źŲź╩ź¾ź╣ż“┤▐żßż┐ź│ź╣ź╚źßźĻź├ź╚żŽ10Ū▄Ī╦ĪŻGoogleż╬źėźĖź═ź╣└«─╣ż╬ż┐żßż╬└’ŠSź©ź¾źĖź¾ż╚Ė½żļż│ż╚ż¼żŪżŁżļĪŻĄšż╦Ė½żļż╩żķżąĪóżĮż╬└Łē”Ė■æųż╬Ų▀▓ĮżŽAIż╬╚»·tĪ”└«─╣żžż╬ć·Å]═ū░°ż╚ż╩żļĪŻż▐ż┐źµĪ╝źČĪ╝żŽ╠Ą┴T╝▒ż╬ż”ż┴ż╦żĮż╬▓ĖįLĪ╩öv┼·ż¼┴ßżżż╩żĻAIżŌĖŁż»ż╩ż├ż┐ż╚┤Čż║żļĪ╦ż“£pż▒żļĪŻ
ż┐ż└żĘ3Ī┴4Ū▄ż╬ź╣źįĪ╝ź╔źóź├źūżŪżŽ1Ī┴2ŃQżĘż½Ęeż┐ż╩żżĪŻź©ź├źĖŖõżŪ╝┬╣įż╬ĮĶ═²ż“żĘż╩żżż╚┴ßĪ╣ż╦źŪĪ╝ź┐ź╗ź¾ź┐żŽźčź¾ź»ż╣żļĪŻØŖż╦śOŲ░╦▌Ślż╬└Łē”ż¼æųż¼żĻĪóÅSż¼╦▄│╩┼¬ż╦╗╚żżĮążĘż┐żķż┐ż▐ż├ż┐żŌż╬żŪżŽż╩żżĪ╩║ŻżŽż▐ż└ż▐ż└╠ż└«▌^żŪĖČĖņżŪŲ╔ż▐żČżļż“įuż╩żżĪ╦ĪŻ
▐köĄ(sh©┤)Īóźóźļź┤źĻź║źÓĪóżŌżĘż»żŽźūźĒź░źķźÓĖ”ē|ŪvĪó│½╚»Ūvż╦ż╚ż├żŲż╬źßźĻź├ź╚żŌĮj(lu©░)żŁżżĪŻż╩ż╝ż╩żķ│žØ{żŽ╗@┼┘ż¼ØŁ═ūż╩ż│ż╚ż½żķ32źėź├ź╚µć┼┘ż╬╔ŌŲ░Š«┐¶┼└ż╬╗╚├ōż¼ĖĮėXķcż▒żķżņż╩żżĪŻżĮż╬32źėź├ź╚ż╬ź│Ī╝ź╔ż“Googleż╦┼ŽżĘĪóTPUæųżŪŲ░║ŅżĄż╗żļż╚4Ū▄Å]ż»Ų░║ŅżŪżŁżļĪŻTPUż½żķÅBżŽż║żņżļż¼Īó╔w─Ļż╬─_ż▀Ī╩źčźķźßĪ╝ź┐Ī╦żŌ1/4ż╚ż╩żļż│ż╚ż½żķĪóźŌźąźżźļżžż╬·t│½(─╠Š’100MB░╩▓╝ż¼źŌźąźżźļżžż╬┼ļ║▄ß×▓─ż╬źĻź▀ź├ź╚ż╚╩╣żżżŲżżżļ)Īóż╣ż╩ż’ż┴Google PlayæųżŪż╬╣Ō┼┘ż╬AIźūźĒź░źķźÓ╝┬äóż“┐õ┐╩ż╣żļĖČŲ░╬üż╚żŌż╩żļĪŻż│ż╬┼└ż½żķżŌ╝Īż╩żļGoogleż╬└’ŠSż¼╗Ūż©żļĪŻ
┐▐35ż╦┐āż╣żĶż”ż╦Īó5ĘŅ░╩æTż╬Google┤žŽóż╬Š╩¾ż“×Rż├żŲż▀żļż╚Īó2016ŃQ7ĘŅż╦TPUż“IPź│źóż╚żĘżŲź┘ź¾ź┴źŃĪ╝┤ļČ╚żŪżóżļźšźķź¾ź╣ż╬GreenWaves Technologiesż╦─¾ČĪżĘżŲżżżļĪ╩╗▓╣═½@╬┴98Ī╦ĪŻź┐Ī╝ź▓ź├ź╚żŽ└ż─c║ŪĮķż╬╦▄│╩IoTź┴ź├źūż└Ī╩ć@Š╬Ī¦GAP8 12 GOPSĪó20mW 2017ŃQ2ĘŅź┴ź├źūĪ╦ĪŻØiĮężĘż┐ż¼ĪóTPUż“ź░Ī╝ź░źļż╬ź╦źÕĪ╝źķźļĄĪ│Ż╦▌ŚlĪ╩GNMTĪ¦Google Neural Machine TranslationĪ¦╗▓╣═½@╬┴99, 100Ī╦ż╦żŌ┼¼├ōżĘżŲ┘Jż╦▒┐├ōżĘżŲżżżļż╚ż╬ż│ż╚ż└ĪŻStanfordĮj(lu©░)│žżŪżŌŲ▒══ż╬Ų░żŁĪ╩╗▓╣═½@╬┴72, 73Ī╦ż“żĘżŲż¬żĻĪóĄĪ│Ż╦▌ŚlĪ╩▓╗╠mŪ¦╝▒żŌŲ▒══Ī╦żŽAI┤žŽóżŪ║ŪżŌź█ź├ź╚ż╩ōļ░Ķż└ĪŻ
╬╠╗ę▓ĮČ\ĮčĪ╩QuantizationĪ╦Ī┴▒ķōQź╣źįĪ╝ź╔źóź├źūż╬├▒ĮŃż╩Š}╦Ī
źŽĪ╝ź╔ź”ź¦źóż╦┤žżĘżŲżŽŠ╩¾ż¼Įo│½żĄżņżŲżżż╩żżż¼ĪóżŪżŽ▐köüż╔ż╬żĶż”ż╦8źėź├ź╚ż╦╬╠╗ę▓Įż╣żļż╬ż½ż¼ē¶żĻż┐żż┼└żŪżóżļĪŻ2016ŃQ5ĘŅ18Ų³ż╬TPUż╬╚»╔Įż╦└Ķ╬®ż─ż│ż╚2ĮĄ┤ųØiż╬5ĘŅ3Ų³ż╦Googleż╬Pete WardenĢ■ż╬źųźĒź░ż╦TensorFlowæųżŪŲ░║Ņż╣żļ╬╠╗ę▓Įż╬ź│Ī╝ź╔ż¬żĶżėżĮż╬▓“└ŌĄŁĄ£ż¼Įo│½żĄżņżŲżżż┐Ī╩╗▓╣═½@╬┴96Ī╦ĪŻż½ż╩żĻ└@├ō└ŁĪ╩ż└żņżŪżŌį~├▒ż╦╗╚ż©ź╚źķźųźļż╬Š»ż╩żżĪ╦ż╬żóżļ░ĄĮ╠Č\Įčż╚╣═ż©żļĪŻż╩ż¬Īóż│ż╬Pete WardenĢ■żŽĪóĖĄJetPec╝ęż╬CTOżŪĘ╚┬ė├ō▓ĶćĄŪ¦╝▒źĮźšź╚Ī╩Apple Storeż╦ĘŪ║▄Ī¦Deep Brief NetworkĪ¦DBNź┘Ī╝ź╣Ī╦ż“ŪõżĻĮążĘż┐╠└ĶĪó2014ŃQžöż╦Googleż╦▓±╝ęż¼āA╝²żĄżņż┐Ęą╬“ż“Ęeż─Ī╩╗▓╣═½@╬┴97Ī╦ĪŻæųĄŁż╬TPUż╬│½╚»ŠÆŠ}ż╚Ų▒żĖ╗■┤³ż└ĪŻ
┐▐37ż╦╬╠╗ę▓Įż╬źšźĒĪ╝ż“┐āż╣ĪŻ╗▓╣═½@╬┴96ż╬┐▐ż“ż▐ż╚żßż┐ĪŻ32źėź├ź╚╔ŌŲ░Š«┐¶┼└▒ķōQż“ĪóŲŌŗż╬ż▀8źėź├ź╚ż╬╔w─Ļ┼D┐¶öĄ(sh©┤)╝░żŪźŪĪ╝ź┐/─_ż▀Č”ż╦╝ŖōQż╣żļĪŻ─_ż▀Ī╩WeightĪ╦żŽĄ£Øiż╦ź¬źšźķźżź¾żŪ╝ŖōQżĘżŲżŌżĶżżżŽż║ż└ĪŻ╠õ¼öżŽĪó╝┬źŪĪ╝ź┐Ī╩Ų■╬üØŖ─¦ź▐ź├źūĪóĮą╬üØŖ─¦ź▐ź├źūż╬ĘQ├═Ī╦ż“ż╔ż╬żĶż”ż╦ĮĶ═²ż╣żļż½żŪżóżļĪŻ┐▐żŪżŽīÖ└Ł▓Į┤ž┐¶Ī╩Rectified Linear┤ž┐¶/źķź¾źū┤ž┐¶Ī¦ReLuĪ╦ż“╬Ńż╚żĘżŲ╗╚├ōżĘż┐ĪŻżĮż╬8źėź├ź╚żŪż╬ReLu▒ķōQż╬Øiż╦źŪĪ╝ź┐ż“32źėź├ź╚ż½żķ8źėź├ź╚ż╦╩č┤╣ż╣żļĪŻ
╩č┤╣ż╬öĄ(sh©┤)╦ĪżŽĪóŲ■╬üż╬32źėź├ź╚źŪĪ╝ź┐ŲŌż╬Maxż╚Minż╬┤ųż“256ż╦╩¼│õżĘżŲĪó└■Ę┴ż╦0-255 (8źėź├ź╚ż╬┼D┐¶╔ĮĖĮż╦╩č┤╣)żŪ│õżĻ¤²ż▒żļĪŻż╩ż¬ż│ż╬└■Ę┴ż╦│õżĻ¤²ż▒żļŠ}╦ĪżŽDeep CompressionĪ╩╗▓╣═½@╬┴45Ī╦żŪ╗╚├ōżĄżņżŲżżżļŠ}╦Īż╚Ų▒żĖżŪżóżļĪŻReLuż“8źėź├ź╚żŪ▒ķōQżĘż┐ĖÕĪóØÖ╬╠╗ę▓Įż“╣įż”ĪŻīÜŖõż╬┐▐żŽ¾H┴žż╬²ŗ├µāįµćż“║’Į³żĘź╣źĻźÓ▓ĮżĘż┐żŌż╬żŪżóżļĪŻżŌż┴żĒż¾Īó╬╠╗ę▓Įż¼Įą═ĶżŲżżż╩żż▒ķōQż¼żóżņżążĮż╬ŗ╩¼żŽ32źėź├ź╚╔ŌŲ░Š«┐¶┼└żŪ▒ķōQż╣żļż╚ż╬ż│ż╚ż└ĪŻ
▓▌¼öżŽż┴żńż├ż╚żĘż┐ĖĒ║╣ż¼╚»Ö┌ż╣żļ┼└ż╬żĶż”ż└ĪŻ╬╠╗ę▓Įż╬║▌ż╬┤▌żßĖĒ║╣żŪżóżļĪŻŠ▄║┘żŽLibraryĪ╩╗▓╣═½@╬┴96ĪóBlog╗▓Š╚Ī╦ż“Ų╔ż▀═²▓“ż╣żļØŁ═ūż¼żóżļĪŻStanfordĮj(lu©░)│žż¬żĶżėUC Berkleyż╬Deep Compressionŗ“ģż╚ż╬Ą─ébż¼żóż├ż┐Ī╩╗▓╣═½@╬┴96ż╬ź│źßź¾ź╚┼ĻąM═¾Ī╦ĪŻPete WardenĢ■ż╬┴TĖ½żŽĪóDeep CompressionżŽ▒ķōQ╬╠ż¼¾Hż╣ż«żļż╚ż╬ż│ż╚żŪżóż├ż┐ĪŻ
Č\Įč┼¬ż╦żŽźĘź¾źūźļż└ż¼ĪóŲ│Ų■ż╬ŪžĘ╩Ī╩źŪĪ╝ź┐ź╗ź¾ź┐ż╬▒ķōQ╬╠ż╬╗ž┐¶┤ž┐¶┼¬ż╩╗\▓├Ī╦ż╚╚Įéā═²Įy(t©»ng)Ī╩ż╚żŌż½ż»ĮĶ═²╗■┤ųż╬ø]Į╠Ī╦ż¼ČĮ╠Ż┐╝żżĪŻµ£öüż╬Ų░żŁż“Ė½żŲżżżļż╚TensorFlowż╬šJ░Žż╚żżż”▄|żĻż“═┐ż©ż╩ż¼żķĪóź©ź├źĖ/IoTżžż╬╝┬╣įĮĶ═²öĪ╣įż“▓├Å]▓ĮżĄż╗żļż╚żżż”└’ŠSż¼╔ŌżŁĮążŲż»żļĪŻTPUżŽLSIżŌżĘż»żŽIPż╚żĘżŲżĮż╬└’ŠSź│źóż╚żĘżŲ░╠Åøż┼ż▒żķżņżļż╚Ė½żļż│ż╚żŌżŪżŁżļĪŻ
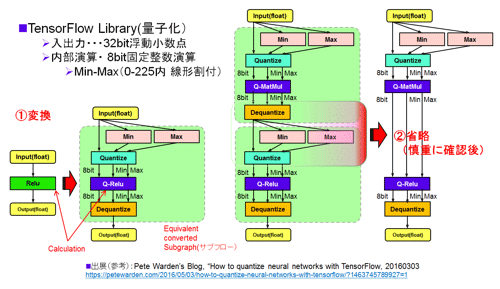
┐▐37 źŪĪ╝ź┐╬╠╗ę▓Įż╬Š}ĮńĪĪĪ╩Pete WardenĢ■ż╬Blog(╗▓╣═½@╬┴96)ż“╗▓╣═ż╦║Ņ└«żĘż┐Ī╦
(2)Deep CompressionĪĪ(StanfordĮj(lu©░)│žż╩ż╔) Ī┴ĘQ═ū┴ŪČ\ĮčĪ┴
┐▐35ż╦┐āż╣żĶż”ż╦ĪóStanfordĮj(lu©░)│žż╬Son HanĢ■żķż╬▐kŽóż╬╚»╔ĮĪ╩╗▓╣═½@╬┴101Īó45Īó46Ī╦ż“ź┘Ī╝ź╣ż╚żĘżŲĪóUC Berkleyż╬źßź¾źąĪ╝ż¼▓├ż’żĻĪó╣įż├ż┐║Ū┐Ęż╬ź═ź├ź╚ź’Ī╝ź»źŌźŪźļSqueeze Netżžż╬┼¼├ōĪ󿥿ķż╦żŽStanfordĮj(lu©░)│žż╬ĄĪ│Ż╦▌Ślż╬└ņ╠ń▓╚ż┐ż┴ż╚ż╬Č”Ų▒│½╚»żŪżóżļNMT(Neural Machine TranslationĪ¦ź╦źÕĪ╝źķźļĄĪ│Ż╦▌Śl)żžż╬┼¼├ōż╚Īóż½ż╩żĻĮj(lu©░)ż¼ż½żĻż╦Ė”ē|│½╚»ż¼╣įż’żņżŲżŁż┐ĪŻ
╦▄╣ÓżŪżŽĪóŲ¾ż─ż╬éb╩Ėż“░Ęż”ĪŻ▐kż─ų`żŽ2015ŃQ10ĘŅż╦╚»╔ĮĪóPruningż╦┤žżĘżŲ░Ęż├ż┐éb╩ĖĪóŲ¾ż─ų`żŽĪó╬╠╗ę▓Įż¬żĶżėźŽźšź▐ź¾╔õęÄ(gu©®)▓Įż“┤▐żßż┐Deep Compressionż“ėæ×│┼¬ż╦░Ęż├ż┐╦▄╠┐ż╬éb╩ĖżŪżóżļĪŻ
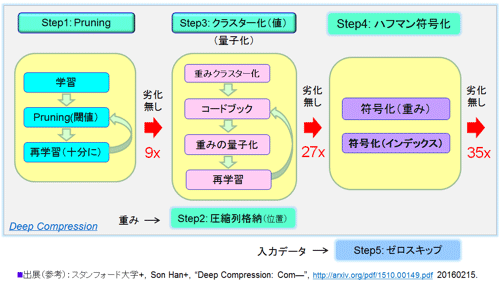
┐▐38ĪĪDeep Compressionż╬░ĄĮ╠ż╬ź╣źŲź├źūĪĪĪ╩╗▓╣═½@╬┴45ż“╗▓╣═ż╦żĘżŲ║Ņ└«Ī╦
éb╩ĖĪ╩╗▓╣═½@╬┴45Ī╦ż“╗▓╣═ż╦żĘżŲ┐▐38ż“║Ņ└«żĘż┐ĪŻDeep CompressionżŽ3ż─ż╬PruningĪ󟻟ķź╣ź┐▓ĮĪ╩╬╠╗ę▓ĮĪ╦Ī󿬿ĶżėźŽźšź▐ź¾╔õęÄ(gu©®)▓ĮĪ╩źĒź╣źņź╣Ī╦ż½żķż╩żļ░ĄĮ╠Č\Įčż╬┴ĒŠ╬ż└ĪŻź»źķź╣ź┐▓ĮżŽ╬╠╗ę▓Įż╚Ė└ż’żņżŲżżżļż¼ĪóGoogle╝ęż╬TPUżŪ╗╚├ōżĘżŲżżżļżŌż╬ż╚Č\ĮčŲŌ═ŲżŽ░█ż╩żļĪŻż▐ż┐┐▐38ż╦┐āż╣żĶż”ż╦╝┬║▌ż╦żŽĪóPruningĖÕż╬╗─ż├ż┐─_ż▀ż╬░╠ÅøŠ╩¾ż“░ĄĮ╠ż╣żļ░ĄĮ╠š`│╩Ū╝öĄ(sh©┤)╝░Ī╩CSCĪ¦Compressed Sparse ColumnĪ╦Ī󿥿ķż╦żŽŲ■╬üźŪĪ╝ź┐ż╦×┤żĘżŲ╣įż”ź╝źĒź╣źŁź├źūż¼żóżļĪ╩źŪĪ╝ź┐ż╬░ĄĮ╠ż╦┤žżĘżŲżŽż│ż╬Č\Įčż╬ż▀ż“├ōżżżŲżżżļĪ╦ĪŻż╩ż¬Īóź╝źĒź╣źŁź├źūżŽEyerissż¼╝┬äóżĘżŲżżżļżŌż╬ż╚┴└żżżŽŲ▒══żŪżóżļĪŻ
Š}Įńż“┐āż╣żĶż”Step1Ī┴Step5ż“¤²ĄŁżĘż┐ĪŻż│ż╬5ż─ż╬Stepż╬ż”ż┴ĪóPruningż╚ź»źķź╣ź┐▓ĮżŽ╗@┼┘ż╬╬¶▓Įż╬▓─ē”└Łż¼żóżļż¼ĪóżĮżņ░╩│░żŽźĒź╣źņź╣żŪ╦▄═Ķ╗@┼┘żžż╬▒ŲūxżŽ╠ĄżżĪŻż╩ż¬ĪóPruningż¬żĶżėź»źķź╣ź┐▓ĮżŪżŽ╬¶▓Įż¼ÅŚż│żķż╩żżšJ░ŽżŪż╬░ĄĮ╠ż“╣įż├żŲżżżļĪ╩╬¶▓ĮżŽ0.4%░╩▓╝Ī╦ĪŻ
Ī╩źóĪ╦PruningČ\Įč Ī╩╗▓╣═½@╬┴101Ī╦
Ų³╦▄Ėņż╦Ślż╣ż╚ĪóĪų╗▐ż¬ż╚żĘĪūż╚ż½Īųč“─ĻĪūż╚ż½żįż├ż┐żĻż╬ć@Øiż¼żóżļż¼Īóż╔ż”żŌČ\Įč├ōĖņż╚żĘżŲżŽżżż▐żęż╚ż─ż╩ż╬żŪżĮż╬ż▐ż▐ĪóPruningż“╗╚├ōż╣żļĪŻ─_ż▀ż╬░ĄĮ╠żŽ
(1)─_ż▀ż╬╬╠Ī╩┐¶Ī╦Ī”Ī”Ī”Pruning
(2)─_ż▀ż╬░╠ÅøŠ╩¾Ī”Ī”Ī”░ĄĮ╠š`│╩Ū╝öĄ(sh©┤)╝░
(3)─_ż▀ż╬źėź├ź╚┐¶Ī╩╬╠╗ę▓Į/ź»źķź╣ź┐Ī╝▓ĮĪ╦Ī”Ī”Ī”ź»źķź╣ź┐▓Į
ż╬įÆż─ż╬Š╩¾╬╠ż“żżż½ż╦░ĄĮ╠ż╣żļż½ż╦żóżļĪŻ─_ż▀ż╬╬╠ż“žōżķżĘĪó─_ż▀ż╬źėź├ź╚┐¶ż“╣╩żļĪŻżĘż½żĘĪó╩└│▓ż╚żĘżŲ (2)ż╬─_ż▀ż╬░╠ÅøŠ╩¾ż¼ØŁ═ūż╚ż╩żļĪŻ╗▐ż“═Ņż╚żĘżŲ░ĄĮ╠ż╣żļż¼Īóż╔ż│ż╬╗▐ż“╗─żĘż┐ż╬ż½ż“│ąż©żŲż¬ż»ØŁ═ūż¼żóżļĪŻ╦▄Č\ĮčżŪżŽĪó└ņ├ōż╬źßźŌźĻĪ╩šÅź▐ź╚źĻź»ź╣Ī╦ż“├ō┴TżĘżŲżżżļĪŻSRAMż└ĪŻ
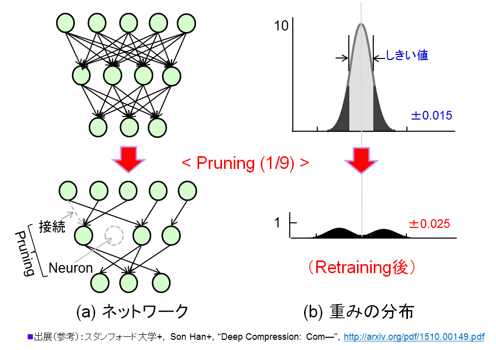
┐▐39 PruningČ\Įčż╬└Ō£½ ĪĪ(a) ź═ź├ź╚ź’Ī╝ź»ĪóĪĪ(b) ─_ż▀ż╬╩¼╔█ż╬╩č▓Į
╗▓╣═½@╬┴101ż“╗▓╣═ż╦║Ņ└«
Pruningż╬Š}ĮńĪ╩╗▓╣═½@╬┴101Ī╦
┐▐39(a)ż╬ź═ź├ź╚ź’Ī╝ź»ż╬┐▐ż╬żĶż”ż╦Īó╔į═ūż╩Īų╗▐/└▄¶öĪūż“żĮż«═Ņż╚żĘĪóĪųź╦źÕĪ╝źĒź¾Īūż“║’Į³ż╣żļĪŻżĮż╬×┤ō■(j©┤)ż╚ż╩żļż╬żŽ┐▐39(b)ż╦┐āż╣╔į═ūż╩żŌż╬żŪżóżļĪŻ┐▐(b)żŌéb╩Ėż“╗▓╣═ż╦║Ņ└«żĘż┐ĪŻæųŖõż╬┐▐ż¼║ŪĮķż╬│žØ{ż╦żĶżĻįuż┐─_ż▀ż╬╩¼╔█ż“┐āż╣ĪŻż│ż╬Šņ╣ńżŽĪ▐0.015ż╬┤ųż╦ż█ż╚ż¾ż╔ż╬żŌż╬ż¼Ų■ż├żŲżżżļĪŻPruningż╬×┤ō■(j©┤)żŽĪó─_ż▀ż╬├═ż¼Š«żĄżżżŌż╬żŪżóżļĪŻż╩ż╝ż╩żķĪó├═ż¼Š«żĄżżż╬żŪ╝Ī├╩żžż╬▒Ųūxż¼Š»ż╩żżż½żķżŪżóżļĪŻDeep CompressionżŪżŽĪųżĘżŁżż├═Īūż“└▀─ĻżĘżŲ═Ų╝Žż╩ż»Pruningż╣żļĪŻż▐ż┐─_ż▀ż¼µ£żŲź╝źĒż╬╗■ĪóżŌżĘż»żŽĮą╬ü├═ż¼ź╝źĒż╬╗■ź╦źÕĪ╝źĒź¾śOöüżŌ║’Į³ż╣żļĪŻżĘżŁżż├═ż╬└▀─Ļż╬öĄ(sh©┤)╦Īż╦żŽŲ╚śOż╬Š}╦Īż¼Ų■ż├żŲżżżļżķżĘżżĪŻżóż▐żĻ£½│╬ż╦Į±ż½żņżŲżżż╩żżĪ╩ĘQ┴ž╦Ķż╦Pruningż“ż╣żļż╚ż½Īóµ£źčźķźßĪ╝ź┐ż“ż╔ż╬══ż╦╩¼│õż╣żļż½ż╬Š}╦ĪżķżĘżżĪ╦ĪŻ
║’Į³żĘż┐ĖÕĪó║Ų│žØ{ż“Ę½żĻ╩ųż╣ĪŻ│žØ{źņĪ╝ź╚ż“1/10ż╦═Ņż╚żĘżŲŃæųtż╦╣įż”ĪŻżėż├ż»żĻżĘż╩żżżĶż”ż╦żµż├ż»żĻżõżļż╬żŪ╗■┤ųż¼²Xż½żļĪŻ║’Į³żĘż┐ĖÕż╬─_ż▀ż╬╩¼╔█ż“(b)ż╬▓╝Ŗõż╬┐▐ż╦┐āżĘż┐ĪŻżĮż╬┐¶żŽ1/9ż╚ż╩ż├ż┐ĪŻ╩¼╔█żŽĮķ┤³ėX▌åżĶżĻ╣Łż¼żĻż“Ęeż─ĪŻźūźķź╣Ī”ź▐źżź╩ź╣ż╬2ż─ż╬┘ćæä╩¼╔█ż╬Ę┴ż╦ż╩ż├żŲżżżļ┼└ż¼ČĮ╠Ż┐╝żżĪŻ═▐öU└ŁĪóČĮ╩│└ŁźĘź╩źūź╣ż“Žó„[żĄż╗żļĪŻ
żĄżŲĪóż│ż╬Č\Įčż╬ź¬źĻźĖź¾żŽ30ŃQØiż╦┴╠żļĪŻ╗▓╣═½@╬┴102Īż103, 104ż╦żóżļżĶż”ż╦Īó1990ŃQØiĖÕż╦│╬╬®żĘż┐Č\Įčż╬źĻźąźżźąźļżŪżóżļĪŻØŖż╦Yann LeCunĢ■Ī╩╗▓╣═½@╬┴103Ī╦ż╦żĶżĻĪóż½ż╩żĻŃæųtż╦ĖĪŲżżĄżņżŲżżżļĪŻ║Ų│žØ{Īóż▐ż┐ż½ż╩żĻ╗■┤ųż╬²Xż½żļ┼└ĪóĖ·▓╠ż¼1/8żŪżóżļ┼└┼∙Īó┘Jż╦╠¾30ŃQØiż╦╩¾╣żĄżņżŲżżżļĪŻżĄżķż╦▐k╩ŌŲ¦ż▀╣■ż▀Īóź©źķĪ╝┤ž┐¶ż╬2╝Ī╚∙╩¼├═ż“║ŪŠ»ż╦ż╣żļ─_ż▀ż“║’Į³ż╣żļŠ}╦ĪĪ╩żóżļ┴T╠ŻBP╦Īż╦╣═ż©öĄ(sh©┤)ż¼ŖZżżĪ╦ż“├ōżżżŲżżżļĪŻCNNż╬éb╩Ė╚»╔Įż╬9ŃQØiżŪżóżļĪŻLeCunĢ■żŽż┤┘TżĖż╬żĶż”ż╦ĖĮ║▀żŌźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬└ż─cż“źĻĪ╝ź╔żĄżņżŲżżżļöĄ(sh©┤)ż╩ż╬żŪżóżļ¹|ż╬┤ČŲ░ż“│ąż©żļĪŻ
żĘżŁżż├═ż“Įj(lu©░)żŁż»ż╣żļż╚░ĄĮ╠╬©żŽæųż¼żĻĪóĄšż╦ź©źķĪ╝╬©żŌ╗\▓├ż╣żļĪŻĮj(lu©░)æä╠Žż╩ź═ź├ź╚ź’Ī╝ź»(AlexNet/VGGNetż╬Imagenet/ILSVRC)żŪź©źķĪ╝╬©ż╬ĄK▓Įż¼Įj(lu©░)żŁż»żŲżŌ0.4%µć┼┘ż╚Č╦żßżŲŠ«żĄżż┼└ż╦▓ĪżĄż©żŲżżżļĪŻ╚Óżķż╬║ŪĮj(lu©░)ż╚╚ĮéāżĘż┐░ĄĮ╠╬©żŽ1/9żŪżóżļĪŻ8/9żŽ╔į═ūż╩▒ķōQż└ż├ż┐ĪŻĖÕĮęż╣żļź»źķź╣ź┐źĻź¾ź░Ī╩╬╠╗ę▓ĮĪ╦┤▐żßżŲż╔ż╬µć┼┘╬Óō¶ż╬ź┐ź╣ź»ż╦·t│½żŪżŁżļż½Ī╩┼ŠöĪ│žØ{ż╦╗╚ż©żļĪ╦żŽż▐ż└ē¶żļĖ┬żĻ╩¾╣żŽż╩żżĪŻź╦źÕĪ╝źķźļĄĪ│Ż╦▌Śl(NMT)żžż╬▒■├ō╬ŃżŽĖÕĮęż╣żļĪŻ
░╠ÅøŠ╩¾ż╬░ĄĮ╠Ī╩░ĄĮ╠š`│╩Ū╝öĄ(sh©┤)╝░Ī¦CSC Compressed Sparse ColumnĪ╦
ØiĮężĘż┐żĶż”ż╦ĪóżĘżŁżż├═ż╦żĶżĻżĮż«═Ņż╚żĘż┐└▄¶öĪ╩╗▐Ī╦ż╬░╠Åøż“│ąż©żŲż¬ż»ØŁ═ūż¼żóżļĪŻ╚Óżķż¼▐k╚ų╬üż“Ų■żņżŲżżżļ┼└ż└ĪŻ┐▐40(a)ż╬─_ż▀ź▐ź╚źĻź»ź╣żŪ│ąż©żŲż¬ż»ĪŻź▐ź╚źĻź»ź╣ż“▐kš`ż╬Š╩¾š`ż╦ÅøżŁ┤╣ż©ĪóżĮż«═Ņż╚żĘż┐└▄¶öż“ź╝źĒż╚Ė½ż╩ż╣ĪŻżĄżķż╦µ£öüż╦ź╝źĒż¼¾Hżżż│ż╚ż½żķĪų░ĄĮ╠š`│╩Ū╝öĄ(sh©┤)╝░Īūż“├ōżżżŲź▐ź╚źĻź»ź╣Š╩¾ż“░ĄĮ╠ż╣żļĪŻāö┐¦ż╬ź╝źĒżŽ┘T║▀ż└ż▒ż“ź½ź”ź¾ź╚żĘżŲ░╠ÅøŠ╩¾ż“░ĄĮ╠ż╣żļĪŻ┐▐(a)ż╬▓╝Ŗõż╦┐āżĘż┐╔ĮĄŁż└ĪŻż│ż╬╔ĮĄŁż╬ż┐żßż╦4źėź├ź╚ż¼ØŁ═ūż╚ż╩żļĪŻ15Ė─ź╝źĒż¼Žóż╩żļż│ż╚ż“╣═ż©żļż╚żĮż”ż╩żļĪŻ±T▓╠ĪóPruningżŪÖ┌żŁ╗─ż├ż┐─_ż▀żŽ4źėź├ź╚ż╬░╠ÅøŠ╩¾Ī╩IndexĪ╦ż“Ęeż─ĪŻ░╩æųż¼Pruningż╬Š}Įńż╚ŲŌ═ŲżŪżóżļĪŻż│żņż“źŽĪ╝ź╔ź”ź¦źóż╦╝┬äóżĘż┐ĪŻ
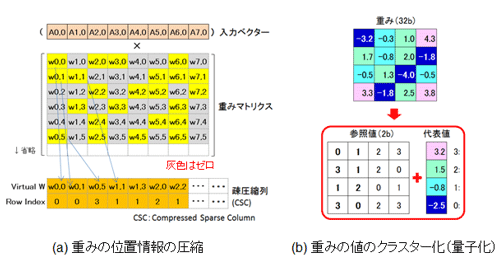
┐▐40ĪĪ(a) ─_ż▀ż╬░╠ÅøŠ╩¾ż╬░ĄĮ╠ĪóĪĪ(b) ─_ż▀ż╬├═ż╬ź»źķź╣ź┐▓ĮĪ╩╬╠╗ę▓ĮĪ╦
╗▓╣═½@╬┴45ż“╗▓╣═ż╦║Ņ└«
Ī╩źżĪ╦─_ż▀ż╬ź»źķź╣ź┐▓ĮĪ╩╬╠╗ę▓ĮĪ╦
─_ż▀ż╬░╠ÅøżŽ░ĄĮ╠żĘż┐ż╬żŪĪó║Ż┼┘żŽ├═ż╬░ĄĮ╠ż└ĪŻDeep CompressionżŪżŽĪóĘQ┴žż┤ż╚ż╦─_ż▀ż“K╩┐Čč╦Īż╦żĶżĻź»źķź╣ź┐źĻź¾ź░żĘżŲżżżļĪŻ┐▐40(b)ż╦┐āż╣żĶż”ż╦Īó─_ż▀ż“ź»źķź╣ź┐źĻź¾ź░żĘĪóź░źļĪ╝źū╚ųęÄ(gu©®)ż¼─_ż▀ż╦ü÷ż’żļĪŻ╝┬║▌ż╬├═żŽź░źļĪ╝źūż╬┬Õ╔Į├═Ī╩CentroidĪ¦32źėź├ź╚Ī╦ż╦ż╩żļĪŻ│žØ{żŽ┐▐40(b)ż╦┐āżĘż┐┬Õ╔Į├═ż╦×┤żĘżŲĪóźąź├ź»źūźĒźčź▓Ī╝źĘźńź¾╦Īż╦żĶżļ│žØ{ż“╚┐▒ŪżĄż╗żļż│ż╚ż╦żĶżĻ╣įż”ĪŻż╩ż¬Īóż│ż╬┬Õ╔Į├═ż╬│žØ{╗■ż╬Įķ┤³├═żŽ║ŪĮj(lu©░)Īó║ŪŠ«├═ż╦×┤żĘżŲČč▐kż╦└▀─ĻżĄżņżļĪŻż│ż╬├▒ĮŃż╩ź»źķź╣ź┐źĻź¾ź░╦Īż└ż¼Īó╚Óżķż¼∙ZŽ½żĘż┐┼└ż└ż╚┐õ╗Īż╣żļĪŻ
Ī╩ź”Ī╦źŽźšź▐ź¾╔õęÄ(gu©®)▓Į
Deep CompressionżŪżŽĪ󟎟šź▐ź¾╔õęÄ(gu©®)▓Įż“├ōżżżŲżżżļĪŻźĒź╣źņź╣ż╬░ĄĮ╠Č\ĮčżŪżóżļĪŻ╦▄£IżŪż╬└Ō£½żŽ│õ░”ż╣żļĪ╩╗▓Š╚½@╬┴45Ī╦ĪŻ
Ī╩ź©Ī╦ź╝źĒź╣źŁź├źū
┐▐40(a)ż╬Ų■╬üź┘ź»ź┐Ī╝ż╚─_ż▀ź▐ź╚źĻź»ź╣ż╬ź▐ź╚źĻź»ź╣Ī”ź┘ź»ź┐Ī╝▒ķōQż╬║▌ż╦ĪóŲ■╬üź┘ź»ź┐Ī╝├═ż╬═ū┴Ūź╝źĒż╬Šņ╣ńżŽżĮż╬ŗ╩¼ż╬▒ķōQż“ź╣źŁź├źūż╣ż╣żļĪŻEyerissżŪżŽ50%µć┼┘ż╬░ĄĮ╠ż╬Ė·▓╠ż¼żóż├ż┐ż¼ĪóEIEż╬Šņ╣ńż╦żŽĪóĄ£Øiż╦Pruningż¼╣įż’żņżŲżżżļż│ż╚ż½żķĖ·▓╠żŽŠ»ż╩żżż╚┐õ▒RżĘżŲżżżļĪŻµ£öüövŽ®╣Į└«µ£╚╠ż╦ĖĪē¶źĘź╣źŲźÓż“╝┬äóżĘż╩żżż╚żżż▒ż╩żżżĶż”żŪż½ż╩żĻ─_ż┐żżČ\Įčż└ĪŻż┴ż╩ż▀ż╦EyerissżŪżŽĪó├▒ĮŃż╦ĘQPEŲŌżŪźŪĪ╝ź┐ż“ĖĪē¶żĘżŲżżżļż└ż▒ż╬żĶż”ż└ĪŻ
░╩æųĪóDeep Compressionż╬ĘQ░ĄĮ╠ż╬Step 1Ī┴5Ī╩┐▐38Ī╦ż“Ū╗├ĖżŽżóżļż¼Īó└Ō£½żĘż┐ĪŻ
░·żŁ¶öżŁĪó╩Ż┐¶ż╬éb╩Ėµ£öüż“╗▓╣═ż╦żĘżŲż▐ż╚żßż┐±T▓╠ż“┐āż╣ĪŻ
┐▐41żŪĪó░ĄĮ╠ż╬źšźĒĪ╝(a)ż╚ĘQź╣źŲź├źūżŪż╬░ĄĮ╠ż╬Ė·▓╠ż╬╬«żņ(b)ż“└Ō£½ż╣żļĪŻźŪĪ╝ź┐ż╦┤žżĘżŲżŽź┘ź»ź╚źļ▒ķōQż“ż╣żļ║▌ż╦Īóź╝źĒżŪżóżņżąź╣źŁź├źūż╣żļĪŻ─_ż▀ż╦┤žżĘżŲżŽĪóPruningż╦żĶżĻ─_ż▀ż╬┐¶ż¼9╩¼ż╬1ż╦ż╩ż├ż┐ĖÕż╦ĪóżĮż╬ź╝źĒ░╩│░ż╬─_ż▀ż╬░╠ÅøŠ╩¾ż╦┤žżĘżŲżŽ░ĄĮ╠š`│╩Ū╝öĄ(sh©┤)╝░ż“┼¼├ōż╣żļĪŻ4źėź├ź╚ż╬░╠ÅøŠ╩¾Ī╩Sparse IndexesĪ╦ż╦ĮĖ╠¾żĄżņżļĪŻź¬Ī╝źąĪ╝źžź├ź╔żŽ16%ż╚ż╩żļĪŻ─_ż▀ż╦┤žżĘżŲżŽź»źķź╣ź┐źĻź¾ź░żŪ╬╠╗ę▓Įż“╣įż”ĪŻ
32źėź├ź╚ż½żķøQ╣■ż▀┴žĪ╩ConvĪ╦żŽ8źėź├ź╚ż╦░ĄĮ╠Īóµ£±T╣ń┴žĪ╩FCĪ╦żŽ5źėź├ź╚ż╦żĮżņżŠżņź»źķź╣ź┐▓ĮżĄżņżļĪŻ8źėź├ź╚żŽ256¹|╬Óż╦╩¼ż▒żķżņĪó5źėź├ź╚żŽ32¹|╬Óż╦╩¼ż▒żķżņż┐ż│ż╚ż╦ż╩żļĪŻ╩┐Č迎(b)ż╦┐āżĘż┐żĶż”ż╦5.4źėź├ź╚ż╚ż╩żļĪŻŲ▒╗■ż╦256¹|╬Óż½ż─32¹|╬Óż╬╣ń╝Ŗ288¹|╬Ó32źėź├ź╚ż╬┬Õ╔ĮĪ╩CentroidĪ╦ż╬─_ż▀ż“ź│Ī╝ź╔źųź├ź»ż╚żĘżŲĘeż─ĪŻAlexNetż╬Šņ╣ńĪóżĮż╬ź¬Ī╝źąĪ╝źžź├ź╔żŽ0.1%ż╚Č╦żßżŲŠ«żĄżżĪŻżĮż╬ĖÕĪ󟎟šź▐ź¾╔õęÄ(gu©®)▓Įż“ĘążŲĪó─_ż▀żŽ╩┐Čč4źėź├ź╚żŪ╔ĮĖĮżĄżņĪó░╠ÅøŠ╩¾żŽ3.2źėź├ź╚żŪ╔ĮĖĮżĄżņżļżĶż”ż╦ż╩żļĪŻ║ŪĖÕż╬╝┬║▌ż╬▒ķōQżŪżŽĪóĄš╔õęÄ(gu©®)▓Į┼∙ż“╣įżż└čŽ┬ż╬▒ķōQż“╣įż”ĪŻ
ż╩ż¬ĪóÅR┴TżĘżŲż█żĘżż┼└żŽĪó┐▐41(a)ż╬╔õęÄ(gu©®)▓Įż╬ŗ╩¼żŽĪó│žØ{ż╬├╩│¼żŪź¬źšźķźżź¾żŪ╣įż├żŲż¬ż»║ŅČ╚żŪżóżļĪŻ╝┬╣įżŪżŽĪóĄš╔õęÄ(gu©®)▓Įż╚źŪĪ╝ź┐ż╬ź╝źĒ├═ż╬ĖĪĮąż¼╝ńż╩EIEż╬║ŅČ╚ż╚ż╩żļĪŻ
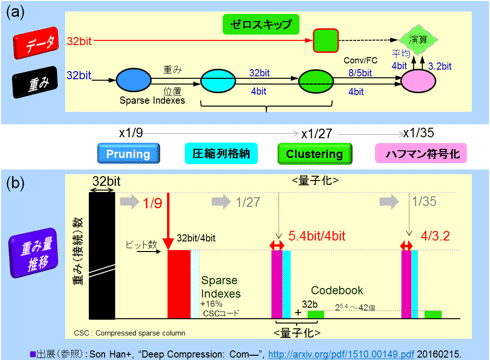
┐▐41 Deep CompressionżŪż╬░ĄĮ╠ż╬╬«żņĪĪĪ╩╗▓╣═½@╬┴45ż“╗▓╣═ż╦║Ņ└«Ī╦
(3)EIE (Energy Efficient Inference EngineĪ¦StanfordĮj(lu©░)│ž)Ī┴źŌźąźżźļ┼¼├ōż“┴└ż”
Øi╣Óż╦░·żŁ¶öżŁĪóDeep Compression┤žŽóżŪżóżļĪŻLSIżžż╬╝┬äóĪ╩CADźņź┘źļĪ╦żĘż┐żŌż╬ż¼▓┐┼┘żŌ└Ō£½żĘżŲżżżļEIE(Energy Efficient Inference EngineĪ¦╗▓╣═½@╬┴46)żŪżóżļĪŻ
╚ÓżķżŽEIEż╬╝┬äóżŪżŽĪó░╩▓╝ż╦┐āż╣┼└żŪŲŌ═Ųż“╚∙─┤┼DżĘż┐żĻĪóéb╩Ėż╬ŲŌ═Ųż“╩čż©żŲżżżļĪŻ
1.źŽźšź▐ź¾╔õęÄ(gu©®)▓ĮĪ╩Ąš╔õęÄ(gu©®)▓ĮĪ╦żŽ┤▐ż▐żņżŲżżż╩żżĪŻ
2.µ£öüż╬źėź├ź╚┐¶żŽ16źėź├ź╚╔w─ĻŠ«┐¶┼└ż¼Įą╚»┼└ĪŻ
3.źŪĪ╝ź┐ż╦ź╝źĒź╣źŁź├źūż“Ų■żņżŲżżżļĪ╩░ĄĮ╠╬©żŽ3Ū▄ż╚Įj(lu©░)żŁżżĪ╦ĪŻ
4.µ£±T╣ńż╦─_żŁż“ÅøżżżŲżżżļĪ╩RNN/LSTMĪóśO─śĖ└Ėņżžż╬·t│½┼∙Ī╦ĪŻ
5.Ąš╔õęÄ(gu©®)▓Įż╚ĪóźŪĪ╝ź┐ż╬ź╝źĒ├═ż╬ĖĪĮąż╦żĶżĻĪó╝┬╣įż¼╣įż’żņżļĪŻ
6.┬Šż╬LSIĄ£╬Ńż╚ż╬╚µ│ė/└@├ōēä(GPU/CPU)ż“▓├ż©ż┐ĪŻ
LSIż╚żĘżŲż╬ĄĪē”żŽĪóPruningĪ󟻟ķź╣ź┐▓ĮĪ╩╬╠╗ę▓ĮĪ╦ż╬Ąš╔õęÄ(gu©®)▓Įż╚Īóź╝źĒ├═ż╬ĖĪĮąż╚ĪóżĮżĘżŲź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬─╠Š’ż╬╝┬╣įżŪżóżļĪŻØŖ╩╠ż╩övŽ®ż╬╝┬äóż¼ØŁ═ūż└ĪŻĄš╔õęÄ(gu©®)▓ĮövŽ®┼∙ż“Ų│Ų■żĘż╩żżż╚Īó100 GOPSµć┼┘ż╬└Łē”ż└ż¼ĪóŲ│Ų■ż╣żļż╚3TOPSż╚30Ū▄ż╬Å]┼┘▓■║¤ż¼įużķżņżļĪŻ─╠Š’ż╬CPU/GPUżŪ╝┬╣įż╣żļż╚ĪóżĮż╬Å]┼┘▓■║¤żŽ3Ū▄µć┼┘ż╚ĄŁżĄżņżŲżżżļĪŻźŽĪ╝ź╔ź”ź¦źóżŪ└ņ├ō▓Įż╣żļż│ż╚ż½żķ▐kĘÕ└Łē”ż¼æųż¼żļż│ż╚ż╦ż╩żļĪŻövŽ®┼¬ż╦żŽźŽźšź▐ź¾╔õęÄ(gu©®)▓ĮĪ╩Ąš╔õęÄ(gu©®)▓ĮĪ╦żžż╬×┤▒■żŽŲ■żņżŲżżż╩żżĪŻ═²Įy(t©»ng)żŽ╔į£½żŪżóżļĪŻ┤ØŹż╚ż╩żļźėź├ź╚┐¶żŽ32źėź├ź╚żŪżŽż╩ż»Īó16źėź├ź╚ż▐żŪ▓╝ż▓żŲżżżļĪŻĄ£Øiż╦ĖĪŠ┌żĘżŲ╬¶▓Įż¼ż╩żżż╚╚ĮéāżĘżŲż╬16źėź├ź╚ż╬║╬├ōż└ĪŻ8źėź├ź╚żŽ╬¶▓Įż¼Ś„żĘż½ż├ż┐ĪŻ
╝ŖōQż╬Š}ĮńżŽ░╩▓╝ż╚ż╩żļĪŻźŪĪ╝ź┐Ī╩ActivationĪ╦ż╬ØÖź╝źĒĖĪĮąż“╣įż”ĪŻ├µ┐┤ż╬öUĖµźµź╦ź├ź╚Ī╩Central Control UnitĪ╦żŪ64Ė─ż╬▒ķōQźµź╦ź├ź╚PE (Processing Element)ż╦ØÖź╝źĒ├═ż╬▒ķōQż“╩¼Ū█żĘżŲżżżļĪŻżęż▐żĮż”ż╩▒ķōQźµź╦ź├ź╚PEż╦▒ķōQż“żĄż╗żļżĶż”ż╦öUĖµżĘżŲżżżļĪŻżĮż╬║▌ż╦ĪóŲ■╬üźŪĪ╝ź┐ż╬├═ż╚źŪĪ╝ź┐ż╬░╠ÅøĪ╩indexĪ╦ż“ź┌źóżŪ┴„┐«ż╣żļĪŻ░╠ÅøŠ╩¾ż“ĖĄż╦×┤▒■ż╣żļ─_ż▀ż╬├═ż╚║Ż┼┘żŽ─_ż▀ż╬░╠Åøż“Ąš╔õęÄ(gu©®)▓Įż╣żļĪŻżĮż╬║▌ż╦SRAMŲŌż╬šÅ╣įš`ż╬├═ż“╗╚żżĪóż▐ż┐ź│Ī╝ź╔źųź├ź»żĶżĻ─_ż▀ż╬╝┬║▌ż╬├═ż“░·ż├─źż├żŲż»żļĪŻżĮż╬ĖÕżõż├ż╚└čŽ┬ż╬▒ķōQż“ż╣żļĪŻ
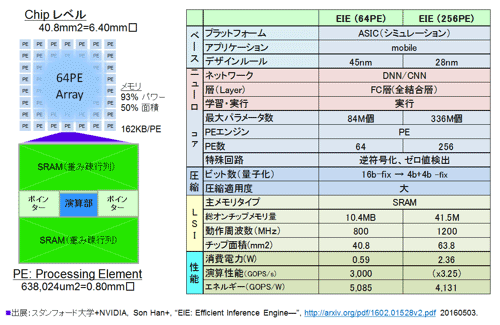
┐▐ 42 EIEż╬▄ć═ū╗┼══ĪĪĪ╩╗▓╣═½@╬┴46ż“╗▓╣═ż╦║Ņ└«Ī╦
ź┴ź├źūż╬╣Į└«ż╚źķźšż╩źņźżźóź”ź╚ż“Īó╗▓╣═½@╬┴46ż“╗▓╣═ż╦żĘżŲ║Ņ└«żĘż┐ĪŻĘQPEżŽ▒ķōQŗż“├µ┐┤ż╦µ£öüż╬75%ż“žéżßżļSRAMĪ╩─_ż▀šÅ╣įš`├ōĪ╦ż¼ŲDżĻ░ŽżÓ╣Į└«ż╚ż╩żļ(memoryż╬žéŃ~╬©żŽ93%ż╦żŌæųżļ)ĪŻSRAMĪ╩─_ż▀šÅ╣įš`Ī╦ż¼źčź’Ī╝ż╦žéżßżļ│õ╣ńżŽ54%ż└ĪŻ▒ķōQśOöüż╬ź©ź═źļź«Ī╝Š├õJżŽ10%ż╚Š«żĄżżĪŻ
AlexNet8, GoogLeNet22,żĮżĘżŲResNet34ż¼┼ļ║▄▓─ē”
┐▐42ż╬īÜŖõż╬╗┼══└Łē”ż“┐āżĘż┐ĪŻź¬ź¾ź┴ź├źūźßźŌźĻż╬╬╠żŽ10MBäėż└ĪŻAlexNetż╬─_ż▀ż╦ØŁ═ūż╩źßźŌźĻ╬╠żŽĪóØÖ░ĄĮ╠żŪ240MBĪ╩32źėź├ź╚┤╣ōQĪ╦ĪóPruningż╚ź»źķź╣ź┐▓ĮĪ╩╬╠╗ę▓ĮĪ╦żŪ27╩¼ż╬1ż╦░ĄĮ╠żĄżņżļż╚ż╣żļż╚Īó9MBµć┼┘ż╬─_ż▀├ōż╬═Ų╬╠ż¼ØŁ═ūż╩ż╬żŪĪóż█ż▄ż«żĻż«żĻAlexNetż╬ź═ź├ź╚ź’Ī╝ź»ż¼│╩Ū╝żŪżŁżļĪŻż▐ż┐ĪóøQ╣■ż▀┴žż¼╝ńöüż╬GoogLeNet22ĪóResNet34żŌ░ĄĮ╠╬©ż“10Ū▄µć┼┘ż╚Ė½└čżŌż├żŲżŌĪó═Š═Ąż“Ęeż├żŲ┼ļ║▄▓─ē”ż└ĪŻ
800MHzŲ░║ŅżŪĪó╝┬╣į3TOPSż╬▒ķōQē”╬üż“ĖžżļĪŻź©ź═źļź«Ī╝Ė·╬©żŽ5TOPS/Wż╚Ų═ĮążĘżŲ╬╔żżĪŻ28nmż“Øi─¾ż╚żĘżŲ4Ū▄ż╦ż╣żļż╚└Łē”żŽĪ▀0.8ż╚ż╩żļżŌĪóż█ż▄8mm│čżŪż½ż╩żĻµ£±T╣ńź┐źżźūż╬ź═ź├ź╚ź’Ī╝ź»Ī╩RNNĪ╦ż¼╝┬ĖĮżŪżŁżĮż”ż└ĪŻ
(4)░ĄĮ╠öĄ(sh©┤)╝░ż╬ż▐ż╚żßĪ”Ī”Ī”šÅ░ĄĮ╠Īó╬╠╗ę▓ĮĪóźĒź╣źņź╣░ĄĮ╠
╔Į7ż╦║Żż▐żŪĮęż┘żŲżŁż┐żżż»ż─ż½ż╬ź╦źÕĪ╝źĒź┴ź├źūż╬░ĄĮ╠Č\Įčż“ż▐ż╚żßż┐ĪŻ╝Ī£IżŪ└Ō£½ż╣żļTrueNorthżŌ╗▓╣═ż╦Ų■żņżŲżóżļĪŻ░ĄĮ╠ż╦żŽĪó─_ż▀ż╚źŪĪ╝ź┐ż╦×┤ż╣żļżŌż╬ż¼żóżļż¼Īó─_ż▀ż╦żŽźįź¾ź»┐¦ż“ĪóźŪĪ╝ź┐ż╦żŽ▓½£u┐¦ż“ż─ż▒żŲĖ½żõż╣ż»żĘżŲżżżļĪŻĘQ×æēäć@ż╬▓╝ż╦╝ńż╦┼¼├ōżĘżŲżżżļ┴žĪ╩LayerĪ╦ż“ĄŁ║▄żĘżŲżóżļĪŻ╬Ńż©żąEIEżŽ╝ńż╦FC┴žĪ╩µ£±T╣ń┴žĪ╦ż╦ŠÆų`żĘżŲżżżļĪŻżĮżņż╦×┤żĘżŲEyrissżŽCONV┴žĪ╩øQ╣■ż▀┴žĪ╦ż╦ØŖ▓ĮżĘżŲżżżļĪ╩╗▓╣═½@╬┴92ż╦żŽµ£±T╣ń┴žżŪż╬ĖĪŲżżŌ╣įż├żŲżżżļĪ╦ĪŻ
ź┴ź├źūżŪĖ½żļż╚ĪóTPUĪóEIEĪóIoEż¼└čČ╦┼¬żŪĪóEyerissżŽź¬Ī╝źĮź╔ź├ź»ź╣ż└ĪŻ╝ŖōQ╝ńöüĘ┐żŪźŪĪ╝ź┐ż╬░ĄĮ╠(ź╝źĒź╣źŁź├źū┤▐żß)ż“ŗī▐k═ź└Ķż╚żĘżŲżżżļż╚Ė½żļż│ż╚ż¼żŪżŁżļĪŻ
╔Į7ż╬żĶż”ż╦░ĄĮ╠ż“3ż─ż╦╩¼▀`ż╣żļż│ż╚ż¼żŪżŁżļĪŻšÅ░ĄĮ╠żŽĪó├▒ĮŃż╦ź╝źĒż╚Ė½ż╩żĘżŲź½ź├ź╚żĘżŲżĘż▐ż”░ĄĮ╠╦Īż╚żĘżŲż▐ż╚żßżŲżżżļĪŻź©źķĪ╝╬©ż╦▒Ųūxż¼ĮążļŠņ╣ńż¼żóżļĪŻ╬╠╗ę▓ĮżŽĪóżĮżņżŠżņż╬Š}╦Īż╦żĶżĻ├═ż“ÅøżŁ┤╣ż©żļż│ż╚ż╦żĶżĻźėź├ź╚┐¶ż“░ĄĮ╠żĘżŲżżżļĪŻźĒź╣źņź╣░ĄĮ╠żŽ╦▄═ĶĄō╝║ż╬ż╩żż░ĄĮ╠öĄ(sh©┤)╝░ż└ĪŻĪ╩ż╩ż¬Īóź╣źŁź├źū╦ĪżŌźĒź╣źņź╣ż╬Š}╦Īż└Ī╦
Ī╩źóĪ╦šÅ░ĄĮ╠
ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╦ØŖż╦ØŖ─¦┼¬ż╚ż▀żļż│ż╚ż¼żŪżŁżļź╝źĒĪóżŌżĘż»żŽź╝źĒŖZ╩šż╬źŪĪ╝ź┐ż“║’Į³Ī╩PruningĪ╦żĘż┐żĻź╣źŁź├źūżĘż┐żĻż╣żļäė░·ż╩öĄ(sh©┤)╦Īż└ĪŻīÖ└Ł▓Į┤ž┐¶ReLUż¼Ė·▓╠ż“Ū▄╗\żĘżŲżżżļĪŻ└čŽ┬▒ķōQż¼┤╦▄ż╩ż╬żŪ└U╠┐żŪżŌżóżļĪ╩└čż╦żĶżĻČ╦Š«▓ĮżĘĪóŽ┬ż╦żĶż├żŲ┴Ļ£¹żĄżņź╝źĒ▓ĮżĄżņżļĪ╦ĪŻ─_ż▀ż╬Šņ╣ńż╦żŽ¼ś┼¬ż╩░ĄĮ╠żŪĪóźŪĪ╝ź┐ż╬Šņ╣ńż╦żŽŲ░┼¬ż╩░ĄĮ╠ż╚ż╩żļĪŻż½ż─╬ŠöĄ(sh©┤)╦Īż╚żŌż╦└ņ╠ń┼¬ż╩övŽ®ż“Ų■żņżļØŁ═ūż¼żóżļĪŻØŖż╦─_żĻż╬Šņ╣ńż╦żŽ╗─ż├ż┐└▄¶öż“│ąż©żŲż½ż─Īó╝┬╣įżŪżŽ┘ćżĘż»Ų░║ŅżĄż╗ż╩żżż╚żżż▒ż╩żżż╬żŪ╩Ż╗©ż╩░§ō■(j©┤)ż“£pż▒żļĪŻźŪĪ╝ź┐ż╬Šņ╣ńż╦żŽź└źżź╩ź▀ź├ź»ż╩Š}╦Īż¼ØŁ═ūĪ╩EyrissżŪżŽĪóPEŲŌŗżŪż╬ĮĶ═²ż╦é╬ż▐ż├żŲżżżļĪ╦ĪŻµ£±T╣ńż╬Šņ╣ńż╦żŽ└▄¶öż¼╣ŁšJżŪż½ż─1×┤1żŪżóżļż│ż╚ż½żķź╝źĒż╚Ė½ż╩ż╗żļ▓─ē”└Łż¼╣Ōż»Ė·▓╠ż¼Įj(lu©░)żŁżżĪ╩10Ū▄░╩æųĪ¦ĖĄĪ╣∙N─╣?!Ī╦ĪŻżĮż╬ż│ż╚ż½żķØŁ┐▄Č\Įčż└ĪŻ
Ī╩źżĪ╦╬╠╗ę▓Į
TPUżŽ├▒ĮŃż╩└■Ę┴ż╬░ĄĮ╠Ī╩Max-Min├═ż“└■Ę┴ż╦256╩¼╬ÓĪ╦ż╦żĶżĻ8źėź├ź╚▓Įż“╣įż├żŲżżżļĪŻ▐köĄ(sh©┤)ĪóStanfordĮj(lu©░)ż╬äh▓┴Ī╩EIEĪ¦╗▓╣═½@╬┴46Ī╦żŪżŽ8źėź├ź╚żŪżŽ└Łē”╬¶▓Įż¼Įj(lu©░)żŁżżĪ╩AlexNet80%ó¬53%Ī╦ż╚ż╬╩¾╣żŌżóżļĪŻTPUżŪżŽ┼¼├ō╬Ńż╦żĶżĻ╗╚żż╩¼ż▒żŲżżżļż╚żżż”ż│ż╚ż½żŌżĘżņż╩żżĪ╩ż╩ż¬ĪóTPUśOöüż¼źėź├ź╚┐¶▓─╩čżŪżóżļ▓─ē”└ŁżŌżóżļĪ╦ĪŻ
żĮż╬┼└ĪóEIEżŽź»źķź╣ź┐▓Įż╦żĶżĻ░ĄĮ╠╬©ż“æųż▓żŲżżżļĪŻ├▒ĮŃż╦żõżļż╚8bitżŽ╠Ą═²ż└ż¼Ī󟻟ķź╣ź┐▓Įż“╣įż”ż╚╩┐Čč5.4źėź├ź╚(øQ╣■ż▀┴ž8źėź├ź╚Īóµ£±T╣ń┴ž5źėź├ź╚)ż▐żŪ░ĄĮ╠ż¼▓─ē”ż└ż╚╝ń─źżĘżŲżżżļĪŻØŖÖzövŽ®ż¼ØŁ═ūż└ĪŻżĶżĻ䮿╬╣ŌżżöĄ(sh©┤)╦Īż╦ĪóØi£IżŪżŌĮęż┘ż┐ż¼IoEż╬źšźŻźļź┐/ź½Ī╝ź═źļĪ╩─_ż▀Ī╦ż╬źčź┐Ī╝ź¾▓Įż╦żĶżĻ░ĄĮ╠╦Īż¼żóżļĪŻ╣Ō╝Īż╬ź½Ī╝ź═źļźņź┘źļżŪż╬╔õęÄ(gu©®)▓ĮĪ╩ØŖ─¦├ĻĮąĪ╦ż╚Ė½żļż│ż╚żŌżŪżŁżļĪŻżĘż½żĘĪó╣═ż©żĶż”ż╦żĶż├żŲżŽź═ź├ź╚ź’Ī╝ź»ż╬┴žż¼┐╩żÓż│ż╚śOöüż¼Īóź½Ī╝ź═źļż╬├Ļō■(j©┤)▓ĮĪ╩ź▐ź»źĒ▓ĮĪ╦żŪżóżļż½żķ▓┐ż¼▓┐ż└ż½ż’ż½żķż╩ż»ż╩żļĪŻ║ŻĖÕż╔ż╬żĶż”ż╦┐╩żÓż╬ż½ČĮ╠Żż╬żóżļČ\Įčż└ĪŻ
Ī╩ź”Ī╦źĒź╣źņź╣░ĄĮ╠
ŲŌŗżŪż½ż╩żĻ░ĄĮ╠ż¼┐╩żßżąĪóĖ·▓╠żŽ─Ńż»Įążļż╚╣═ż©żķżņżļż¼Īó1.5Ū▄µć┼┘ż╬Ė·▓╠ż¼Ė½╣■żßżļżĶż”ż└ĪŻ
╔Į7 ░ĄĮ╠Č\Įčż╬▐k═„
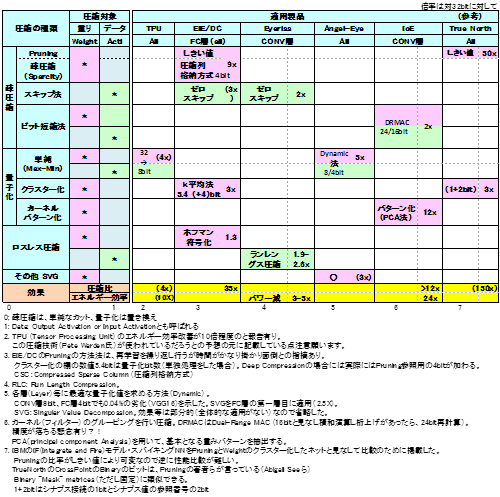
░ĄĮ╠Č\Įčż╦┤žż╣żļż▐ż╚żß
øQ╣■ż▀┴žĪ╩ØŖż╦CĘ┐ż╬CNNĪ╦żŪżŽ═ŠżĻ╗ūżż└┌ż├ż┐║÷żŽŲDżĻż╦ż»żżĪŻĖ·▓╠ż¼╚µ│ė┼¬─Ńżßż╦Įążļż½żķż└ĪŻĪ╩╝Ī£IżŪĮęż┘żļSqueeze NetżŽŲ■żņ╣■ż¾żŪżżżļż¼Ī╦ĪŻ
µ£±T╣ń┴žż“╝ńöüż╚ż╣żļź═ź├ź╚źŌźŪźļżŪżŽĪó└čČ╦┼¬ż╩·t│½ż¼żóżļż╚„[─ĻżĘżŲżżżļĪŻŠņ╣ńż╦żĶż├żŲżŽźąźżź╩źĻĪ”ź│ź═ź»ź╚ż╩żĻźąźżź╩źķźżź║ź╔Ī”ź═ź├ź╚ź’Ī╝ź»ż╬Įą╚ųż½żŌżĘżņż╩żżĪ╩╗▓╣═½@╬┴41Īó42Ī╦ĪŻ
ĮķąMż╬├╩│¼ż½żķ╗■┤ųż¼Ęąż┴ĪóĖĮ╗■┼└(3ĘŅ)żŪżŽ2ĘŅż╬ISSCC2017ĪóĄ┌żė2ĘŅĖÕ╚Šż╬FPGA2017(International Symposium on FPGA 2017)ż╬ŲŌ═ŲżŌ╚Į£½żĘżŲżżżļĪŻį~├▒ż╦Įęż┘żļż╚ĪóøQ╣■ż▀┴žż“ź┐Ī╝ź▓ź├ź╚ż╦ISSCC2017żŪżŽźŪĪ╝ź┐/╔ķ▓┘Č”ż╦╬╠╗ę▓Įż“╣įż”Č\Įčż╬╩¾╣ż¼żóż├ż┐ĪŻ┴ž╦ĶżŪźėź├ź╚┐¶ż“║Ū┼¼▓Įż╣żļŠ}╦ĪĪ╩4-9bitĪ╦Ī󿥿ķż╦żŽ┐┐ż╦ź└źżź╩ź▀ź├ź»Ī╩Real TimeĪ╦ż╦║Ū┼¼źėź├ź╚┐¶ż“ĖĪē¶żĘ╝┬╣įż╣żļöĄ(sh©┤)╦Īż╬╩¾╣ż¼żóż├ż┐ĪŻż½ż╩żĻĖ┬─cż▐żŪĄ═żß└┌ż├ż┐░§ō■(j©┤)ż“£pż▒ż┐ĪŻFPGA2017żŪżŽ1bit(Binary/XNOR) /2bit(ternary)ż╦┤žż╣żļČ\Įčż╬╩¾╣ż¼örż¾ż╦ż╩żĄżņż┐ĪŻż│ż╬Č\Įčż╦┤žżĘżŲżŽżóżļµć┼┘Č\Įč┼¬ż╦öĄ(sh©┤)Ė■└Łż¼Ė½ż©ż─ż─Ń~żĻż▐ż┐▓▌¼öżŌĖ½ż©żŲżŁż┐ėXČĘżŪżóżļĪŻ
░╩æųĪóŗī4ŠŽżŪżŽ4.1£Iż½żķ4.3£Iż╦²Xż▒żŲĪóCNNĪóDNNĪ󿬿Ķżė░ĄĮ╠Č\Įčż╦┤žżĘżŲż╬ź╦źÕĪ╝źĒź┴ź├źūż╬Š▄║┘ż“╩¾╣żĘż┐ĪŻ║ŪĮ¬ż╬ŗī5ŠŽżŪżŽ║ŪŖZż╬Ų░Ė■ż“▓├ż©żļĪŻź╦źÕĪ╝źĒźŌźļźšźŻź├ź»ź┴ź├źūż╚żĘżŲ║ŪŖZ┐ʿʿż╣Łż¼żĻż“Ė½ż╗żļIBMż╬TrueNorthż╚░ĄĮ╠Č\ĮčĪ╩Deep CompressionĪ╦ż╬╝┬äó╬Ńż“Šę▓ż╣żļĪŻ║ŪĖÕż╦╦▄┤¾ąMż╬ż▐ż╚żßż╚żĘżŲŲ░Ė■ż╚║ŻĖÕż╬▓▌¼öż“Įęż┘żļĪŻ
įćĮĖÅRĪ╦╝å└źĢ■ż╬ĖĮ║▀ż╬Ė¬Į±żŽĪóĒ×ķL╠OĮj(lu©░)│ž Įj(lu©░)│ž▒ĪŠ╩¾▓╩│žĖ”ē|▓╩ │žĮčĖ”ē|µ^żŪżóżļĪŻ
╗▓╣═½@╬┴ (1Ī┴88ż▐żŪżŽż│żņż▐żŪż╬Īųź╦źÕĪ╝źĒź┴ź├źū▄ćébĪū╗▓Š╚)
- TeraDeep╝ęż╬┐Ęäóż╬ź█Ī╝źÓź┌Ī╝źĖ
- Market Video, "TeraDeep's Industry-First FPGA-based AI Inference Fabric Speeds Image Recognition, Video Analytics for On-Premise Appliances", October 18, 2016, TeraDeepż╬╝┬ä®┼¬ż╩Press Release/Xilinx/Micron, 20181018.
- XLINX, "TeraDeep's real-time video analytics run on (gasp) FPGA-based Micron/Pico Computing AC-510 platform", XILINXż╬Daily Blog, 20161018.
- Yu-Hsin Chen, Joel Emer and Vivienne Sze, "Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks", 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Eyerissż╬Full Paper╚Ū, 2016ŃQ6ĘŅ18Ų³.
- ┼┼╗ęŠ╩¾ 2016ŃQ10ĘŅ16Ų³,"GoogleĪóIBMĪóAMDĪóNVIDIAż╩ż╔ż¼żĶżĻ╣ŌÅ]ż╩└@├ōźżź¾ź┐Ī╝ź│ź═ź»ź╚ĪųOpen CAPIĪū╚»╔ĮĪŻźĄĪ╝źąż“10Ū▄╣ŌÅ]▓Įż╦ż╣żļż╚"
- Norm Jouppi, Distinguished Hardware Engineer, Google, "Google supercharges machine learning tasks with TPU custom chip", Google Could Platform Blog, 20160518, Google, TPUż╬╚»╔Į
- ┼┼╗ęŠ╩¾, Stacey Higginbotham, "Google Takes Unconventional Route with Homegrown Machine Learning Chips", The Next Platform, May 19, 2016, TPUż╦┤žżĘżŲ╚µ│ė┼¬╗@┼┘ż╬╣Ōż½ż├ż┐┼┼╗ęŠ╩¾, 20160519.
- Pete Warden's Blog, "How to quantize neural networks with TensorFlow", TPUż╦╗╚ż’żņżŲżżżļż╚„[─ĻżĄżņżŲżżżļ╬╠╗ę▓ĮČ\Įč, 20160503.
- IT Media, "GoogleĪó┐═╣®ē¶ē”▒■├ōż╬źĘźŲźŻź¼źżź╔┤ļČ╚ĪųJetPacĪūż“āA╝²"
- EETimes Europe, Peter Clarke, "IoT processor beats Cortex-M, claims startup", TPUż¼IPź│źóĪ╩▓ĶćĄŪ¦╝▒Ī╦ż╚żĘżŲIoTź┴ź├źūż╦┼ļ║▄═Į─ĻĪ╩GAP8Ī╦, 20161104.
- Quoc V. Le & Mike Schuster, "A Neural Network for Machine Translation, at Production Scale", Google Research Blog, 20160927, GNMT(Google Neural Machine Translation)ż╦┤žżĘżŲż╬Šę▓ĄŁĄ£Ī╩éb╩Ėż╬╚»╔Įż╦żóż┐ż├żŲĪ╦
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean, "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation", GNMTż╬éb╩Ė, 2016ŃQ10ĘŅ8Ų³.
- Song Han, Jeff Pool, John Tran, William J. Dally, "Learning both Weights and Connections for Efficient Neural Networks", PruningČ\ĮčĪóź╣ź┐ź¾źšź®Ī╝ź╔Įj(lu©░)│žĪó2015ŃQ10ĘŅ30Ų³.
- Stephen Jose Hanson and Lorien Y Pratt, "Comparing biases for minimal network construction with back-propagation", In Advances in neural information processing systems, pages 177-185, 1989, Įķ┤³ż╬PruningČ\Įč.
- Yann Le Cun, John S. Denker, and Sara A. Solla, "Optimal brain damage", In Advances in Neural Information Processing Systems, pages 598-605. Morgan Kaufmann, 1990, Įķ┤³ż╬PruningČ\ĮčĪ╩└▄¶ö┐¶ż“žōżķżĘż┐Ī╦.
- Babak Hassibi, David G Stork, et al, "Second order derivatives for network pruning: Optimal brain surgeon", Advances in neural information processing systems, pages 164-164, 1993, Įķ┤³ż╬PruningČ\Įč.

