ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(3-3)
ŗī3ŠŽż╬3.3żŪżŽĪóż│żņż▐żŪ│½╚»żĄżņż┐ź┴ź├źūż“ĪóCNNż╚DNN/µ£±T╣ń┴žż╦╩¼ż▒╩¼╬ӿʿŲżżżļĪŻżĮżņżŠżņż╬ź┴ź├źūż¼ż╔ż╬żĶż”ż╩░╠Åøż┼ż▒ż╦żóżļż╬ż½żŌ═²▓“żŪżŁżļżĶż”ż╦ź░źķźš▓ĮżĘżŲżżżļĪŻŗī3ŠŽż╬ż│żņż▐żŪż╬╗▓╣═½@╬┴ż“ż▐ż╚żßżŲżżżļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĪĪĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
3.3ź┴ź├źū└Łē”▐k═„ż╚Č\Įč┼¬ź▌źĖźĘźńź╦ź¾ź░
╦▄£IżŪżŽĪóŗī4ŠŽżŪ└Ō£½ż╣żļ10Ė─ż╬ź┴ź├źūż“įSŌūżŪżŁżļżĶż”ż╦└Łē”▐k═„╔Įż“├ōżżżŲ└Ō£½ż╣żļĪŻż▐ż┐ź░źķźšż“├ōżżżŲĘQź┴ź├źūż╬Č\Įč┼¬ż╩ź▌źĖźĘźńź¾ż“┐āż╣ĪŻ
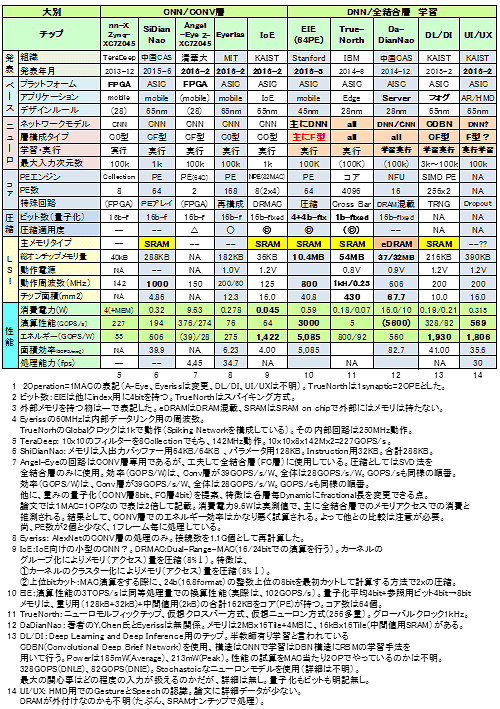
╔Į6 ┬Õ╔Į┼¬ź╦źÕĪ╝źĒź┴ź├źū ╗┼══▐k═„
(1) ╗┼══▐k═„ż╬ŲŌ═Ų
╔Į6ż╬╗┼══żŽ╚µ│ė┼¬żĮżĒżżż╬żĶżż╣Óų`ż“┬ō(li©ón)┘IżĘż┐ĪŻź┴ź├źūź│Ī╝ź╔ć@ż╬ż╩ż½żŪĪóIoEĪóDL/DI(Deep Learning/Deep InferenceĪ¦╗▓╣═½@╬┴86)Ī󿬿ĶżėUI/UX(╗▓╣═½@╬┴87)żŽéb╩Ėż╬ź┐źżź╚źļż½żķ░·├ōżĘżŲ╠┐ć@żĘż┐ĪŻż█ż╚ż¾ż╔ż╬ź┴ź├źūż¼ASICżŪżóżļĪ╩Š»żĘ░·├ōż╦╩ążĻż¼żóż├ż┐Ī╦ĪŻż▐ż║µ£öüż“CNNż╚DNNĪ╩Č╣▒Iż╬DNNĪ╦ż╬ź½źŲź┤źĻĪ╝ż╦╩¼ż▒żŲżżżļĪŻ┴ž╣Į└«Ī╩CĘ┐ż╚ż½CFĘ┐Ī╦ż╬ź┐źżźūż½żķ╚ĮéāżĘżŲŲ¾╩¼żĘżŲżżżļĪŻCNNż╬ź½źŲź┤źĻĪ╝żŪżŽ┴ž╣Į└«C0Ę┐ż¼3ź┴ź├źūĪóCFĘ┐ż¼2ź┴ź├źūżŪżóżļĪŻ
ź╣ź┐ź¾źšź®Ī╝ź╔Įj│žż╬EIE(Energy Efficient Inference EngineĪ¦╗▓╣═½@╬┴46)żŽĪó░ĄĮ╠Č\ĮčĪ╩Deep Compression ╗▓╣═½@╬┴45)├ōż╬ØŖÖzövŽ®ź│źóĖĪŠ┌ż“źŌź┴Ī╝źšż╚żĘż┐ź©ź¾źĖź¾żŪżóżļĪŻCFĘ┐Ī”FĘ┐ż“×┤ō■(j©┤)ż╚żĘżŲżżżļż¼╝ńż╦µ£±T╣ń┴žż“ĖĪŲżż╬×┤ō■(j©┤)ż╚żĘżŲżżżļĪŻż│ż╬ż│ż╚ż½żķDNNż╬ź½źŲź┤źĻĪ╝ż╦Ų■żņż┐ĪŻ
DL/DIż“ż╔ż┴żķż╦Ų■żņżļż½ż½ż╩żĻ╠┬ż├ż┐ż¼ĪóDNN/µ£±T╣ń │žØ{ż╬ź░źļĪ╝źūż╦Ų■żņż┐ĪŻż│ż╬ź┴ź├źūżŽRBMż“│žØ{ż╬┤╦▄ż╚ż╣żļDBN (Deep Brief Network)ż╬ź═ź├ź╚źŌźŪźļż╦øQ╣■ż▀Ī╩ConvolutionalĪ╦ż╬Š}╦Īż“ŲDżĻŲ■żņżŲżżżļĪŻ╦▄═Ķż╩żķ║ĖŖõż╬CNNż╦Ų■żņżļż┘żŁż└ż¼ĪóDBNż“äė─┤ż╣żļż┐żßż╦┤║ż©żŲīÜż╦Ų■żņżŲżżżļĪŻ
╔ĮżŪżŽų`╬®ż─żĶż”ĄŁ║▄żĘżŲżżż╩żżż¼ĪóTrueNorth(╗▓╣═½@╬┴84, 85)żŽż│ż╬╔ĮżŪ═Ż▐kż╬ź»źĒź╣źąĪ╝öĄ(sh©┤)╝░Ī╩╝┬║▌żŽ▓Š„[ź»źĒź╣źąĪ╝öĄ(sh©┤)╝░żŌżĘż»żŽ▓Š„[ź╦źÕĪ╝źĒź¾öĄ(sh©┤)╝░Ī¦╗■╩¼│õ¾H─_ż“├ōżżżļĪ¦5.1£IżŪ└Ō£½Ī╦żŪżóżĻĪóż½ż─ź╦źÕĪ╝źĒźŌźļźšźŻź├ź»ź┴ź├źūżŪżóżļĪŻŲ■╬üż╚Įą╬üż¼źóźņźżėXĪ╩ź»źĒź╣ėXĪ╦ż╦Ū█ÅøżĄżņżĮż╬Ė“┼└ż¼└▄¶öż╚─_ż▀ż“╔ĮĖĮż╣żļĪŻ
ż│żņż╦×┤żĘżŲ┬ŠżŽźąź╣öĄ(sh©┤)╝░żŪżóżļĪŻźąź╣ż╦▒ķōQ├ōż╬ź│źóĪ╩PEĪ¦Processing Engine/ElementĪ╦ż“╩┬š`ĪóżŌżĘż»żŽźóźņźżėXĪ╩ØŁ═ūż╦▒■żĖżŲNoCĪ¦Network on chipż╬┼ļ║▄żĄżņżļĪ╦ż╦Ū█ÅøżĘźŪĪ╝ź┐ż¬żĶżėźčźķźßĪ╝ź┐Ī╩źšźŻźļź┐├═Īó─_ż▀Ī╦ż“źąź╣ż½żķČĪĄļż╣żļĪŻŲ░║Ņź»źĒź├ź»ż╦╚µ╬ѿʿŲ▒ķōQÅ]┼┘żŽ╗\Įjż╣żļĪŻ
źßźŌźĻ║«║▄żŽ─_═ūż╩źšźĪź»ź┐Ī╝ż└ĪŻDaDianNaożŽźąź╣öĄ(sh©┤)╝░żŪżóżļż¼Ī󟬟¾ź┴ź├źūż╬DRAMż╦źčźķźßĪ╝ź┐ż“│╩Ū╝ż╣żļż│ż╚ż╦żĶżĻĪóźčźķźßĪ╝ź┐źóź»ź╗ź╣╗■┤ųż╬ø]Į╠Ī󿥿ķż╦ź╣ź▒Ī╝źķźėźĻźŲźŻĪ╝ż╬Ė■æųĪóżĮżĘżŲżĮż╬±T▓╠ż╚żĘżŲøQ╣■ż▀┴žżŽżŌż╚żĶżĻµ£±T╣ń┴žż╬▒ķōQ└Łē”Ė■æųż“╝{Ąßż╣żļĪŻżĮżņż└ż▒ż╦é╬ż▐żķż║Ų░┼¬║Ų╣Į└«ĄĪē”Ī”│žØ{ĄĪē”ż“żŌ┼ļ║▄żĘż┐╠Ņ┐┤┼¬ż╩ź┴ź├źūż└Ī╩╝┬║▌ż╦żŽCAD╝┬äóż▐żŪĪ╦ĪŻż╩ż¬KAISTż╬DL/DIż¬żĶżėUI/UXżŽČ”ż╦│žØ{ĄĪē”ż“┼ļ║▄żĘż┐ź┴ź├źūżŪżóżļĪ╩╗─Ū░ż╩ż¼żķ═²▓“żŪżŁżļźņź┘źļż╬Š▄║┘Š╩¾żŽĮo╔ĮżĄżņżŲżżż╩żżĪ╦ĪŻ
żĮż╬┬ŠĪó╔Įż╚żĘżŲ─_═ūż╩ź▌źżź¾ź╚ż“æųż▓żļż╚Īó║ŪĮjŲ■╬ü╝ĪĖĄ┐¶ż╦övŽ®ż╬æä╠Žż¼╚µ╬Ńż╣żļĪŻShiDianNaoż╬Ų■╬ü╝ĪĖĄ┐¶żŽ1kżŪżóżĻĪóMNISTż╬32x32ż╬Ų■╬üż“░Ęż”Š«æä╠Žż╩żŌż╬ż└ĪŻ╗┼══Īó╬Ńż©żąŠ├õJ┼┼╬üż“╚µ│ėż╣żļ║▌ż╦żŽ║ŪĮjż╬Ų■╬ü╝ĪĖĄ┐¶ż╦żŌÅR┴Tż¼ØŁ═ūżŪżóżļĪŻ╗─Ū░ż╩ż¼żķŲ■╬üż╬╝ĪĖĄ┐¶ż╬ĄŁ║▄ż╬ż╩żżżŌż╬żŌżóżļĪŻ
░ĄĮ╠Č\Įčż╬┼ļ║▄ėXČĘż“źėź├ź╚┐¶ż╚┼¼├ō┼┘ż╬źņź┘źļżŪ┐āżĘż┐ĪŻ╬Ńż©żąĪ²żŽż½ż╩żĻĮjż¼ż½żĻż╦░ĄĮ╠Č\Įčż“┼¼├ōżĘżŲżżżļżŌż╬ż“┐āż╣ĪŻEIEż╚IoEż¼╬ŠČdżŪżóżļĪŻ░ĄĮ╠ż╬Š▄║┘ŲŌ═Ųż╦┤žżĘżŲżŽĖÕĮęż╣żļĪ╩4.3£IĪ╦ĪŻż╩ż¬EIE/IoEż╬╝┬Ė·źėź├ź╚┐¶żŽĄŁ║▄├═żĶżĻ┤÷╩¼ĮjżŁżżĪŻż▐ż┐TrueNorthżŽ1bit(źąźżź╩źĻĪ¦║ŪŖZżŽź┐Ī╝ź╩źĻ)ż╚Š╬żĄżņżŲżżżļż¼Īó╝┬Ė·┼¬ż╦żŽ╣{ĻJ¾HżżĪŻ
LSIż╚żĘżŲż╬┤÷ż─ż½ż╬└Łē”ż“▓╝├╩ż╦ż▐ż╚żßż┐ĪŻ└Łē”ż“▓Ż╩┬żėż╦╚µ│ėż╣żļż╬żŽČ╦żßżŲÕeĖ▒ż╩Šņ╣ńż¼żóżļĪŻ╗┼══ż╦żĶżĻĮjżŁż»╩čż’żļĪŻż▐ż║źßźŌźĻ║«║▄ż╬Ń~╠ĄĪó│žØ{ĄĪē”ż╬Ń~╠ĄĪó╝Īż╦ź═ź├ź╚ż╬╣Į└«Ę┐Ī╩C0/C1ĪóĄ┌żėCF/FĘ┐)ĪóżĮżĘżŲæä╠ŽĪ╩Ų■╬ü╝ĪĖĄ┐¶Ī╦ż╦żĶżĻĮjżŁż»░█ż╩żļż╬żŪé╬┴Tż¼ØŁ═ūż└ĪŻ
(2)ĘQź┴ź├źūż╬ź▌źĖźĘźńź¾
ĘQź┴ź├źūż╬ź▌źĖźĘźńź¾ż“ż’ż½żĻżõż╣ż»ż╣żļż┐żßż╦Īó┴ž╣Į└«Ī╩CONV┴ž/FC┴žĪ¦Fully ConnectedĪ╦ż╚░ĄĮ╠ż╬Ń~╠ĄżŪ╩¼ż▒ź▐ź├źįź¾ź░żĘż┐Ī╩┐▐23Ī╦ĪŻź┴ź├źūż╬ź│Ī╝ź╔ć@ż╬▓Żż╦ź©ź═źļź«Ī╝Ė·╬©Ī╩GOPS/s/WĪ╦ż“┼║ż©ż┐ĪŻżĮż╬├═ż╦żĶżĻź▐Ī╝ź»ż╬ĮjżŁżĄż“╩čż©ż┐ĪŻ1TOPS/s/W░╩æųż└ż╚ĮjżŁż╩ź▐Ī╝ź»ż“╗╚├ōżĘż┐ĪŻ
ż▐ż┐Īó╔Į6ż╦żŽż╩żżGoogleż╬TPUĪ╩╗▓╣═½@╬┴Īó88Ī╦ż“źŪĪ╝ź┐ż╚żĘżŲ▓├ż©ż┐ĪŻē|Č╦ż╬Ę┴ż╚żĘżŲĪóCNNż╬C0Ę┐ż╬źŌźŪźļżŪżóżļSqueezeNet (Deep Compressionż“┼¼├ōĪ¦╗▓╣═½@╬┴50)Īóż▐ż┐NMTĪ╩Neural Machine TranslationĪ¦ź╦źÕĪ╝źķźļĄĪ│Ż╦▌ŚlĪ¦RNNźŌźŪźļź┘Ī╝ź╣Īó╗▓╣═½@╬┴72Īó73Ī╦ż╦PruningČ\Įčż“¤²▓├żĘż┐±T▓╠żŌ▓├ż©żŲżóżļĪŻżĄżķż╦TrueNorthżŌŪ█ÅøżĘż┐ĪŻ░ĄĮ╠ż╬£å┼└ż½żķĖ½żļż╚Īóź╣źčźżźŁź¾ź░ż“PruningĪ╩śOŲ░żŪ╣įż├żŲżżżļĪ╦Īó└▄¶öż“źąźżź╩źĻ╬╠╗ę▓ĮĪ󿥿ķż╦─_ż▀ż“ź»źķź╣ź┐╩¼╬ӿʿŲżżżļż╚╬Óō¶żŪżŁżļż╚╣═ż©ż┐Ī╩¾HŠ»╠Ą═²ż¼żóżļż¼Ī╦ĪŻ
Įķ┤³(1Ī┴2ŃQØi)ż╬CNNĪó│žØ{ĄĪē”ż“Ń~ż╣żļżŌż╬Īó║Ū┐Ęż╬CNNĪ󿥿ķż╦ź╣ź┐ź¾źšź®Ī╝ź╔Įj│ž─¾Š¦ż╬Deep CompressionĪ╩DCĪ╦ż“┼¼├ōżĘż┐żŌż╬ż¼ż’ż½żļżĶż”ż╦Īóź░źļĪ╝źįź¾ź░żĘż┐ĪŻ
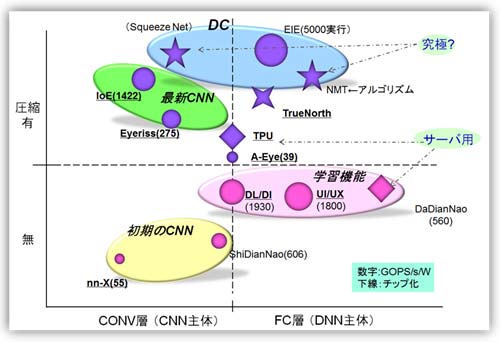
┐▐23 ĘQź┴ź├źūż╬ź▌źĖźĘźńź╦ź¾ź░
ŗī3ŠŽżŪżŽ3.1£IĪ┴3.3£Iż╦żŲĪó┤╦▄┼¬ż╩övŽ®╣Į└«ż╬┤╦▄Ī╩ØŖż╦øQ╣■ż▀┴žĪ╦ż╦┤žżĘżŲ└Ō£½ż“╣įżżĪóż▐ż┐║ŪŖZĪ╩2016ŃQØi╚ŠĪ╦ż▐żŪż╬ź╦źÕĪ╝źĒź┴ź├źūż╬▄ć═ūż“ėæ×│┼¬ż╦└Ō£½żĘż┐ĪŻ╝ĪŠŽĪ╩ŗī4ŠŽĪ╦░╩æTżŪżŽĪóź┴ź├źūż╬Š▄║┘ż“CNN├ō(4.1£I)ĪóDNN├ō(4.2£I)ĪóżĮżĘżŲ░ĄĮ╠Č\Įč(4.3£I)ż“├ōżżż┐ź┴ź├źūż╦╩¼ż▒żŲ└Ō£½ż╣żļĪŻ
╗▓╣═½@╬┴ (1Ī┴55ż▐żŪżŽŗī1ŠŽż╚ŗī2ŠŽż“╗▓Š╚)
- Jiantao Qiu, Jie Wang, Song Yao, Kaiyuan Guo, Boxun Li, Erjin Zhou, Jincheng Yu, Tianqi Tang, Ningyi Xu, Sen Song, Yu Wang and Huazhong Yang, "Going Deeper with Embedded FPGA Platform for Convolutional Neural Network",2016ACM pp.26-, FPGA'16, ╦{▓┌Įj│žĪóAngel Eye, 2016222
- Jeff Gehlhaar, "Neuromorphic Processing: A New Frontier in Scaling Computer Architecture", ASPLOS'14:Architectural Support for Programming Languages and Operating Systems, http://www.cs.utah.edu/asplos14/files/Jeff_Gehlhaar_ASPLOS_Keynote.pdf, https://dl.acm.org/purchase.cfm?id=2564710&CFID=687971028&CFTOKEN=91213122ĪóQualcomm, NeuromorphicČ\Įč, 20140304.
- Qualcomm Snapdragon Blog, "Snapdragon 820 Automotive processors debut at CES 2016", Qualcomm, SD820A, 20160106.
- Qualcomm ╗┼══Į±, "Qualcomm Snapdragon 820A: Industry's first automotive grade SoC with integrated X12 LTE modem", Qualcomm, SD820A╗┼══Į±, 2016ŃQ.
- EETimes, Junko Yoshida, ┼┼╗ęŠ╩¾Īó2016ŃQ1ĘŅ27Ų³, "Google's Deep Learning Comes to Movidius/ Moving machine vision from data centers to devices", Movidiousż╬Googleż╚ż╬Č”Ų▒│½╚» ╚»╔Į (źżź¾źŲźļāA╝²ĖÕżŌśO╝ęź█Ī╝źÓź┌Ī╝źĖżŽ╩čż’żķż║ĪóDJIż╚ż╬źūźĒźĖź¦ź»ź╚ŲŌ═ŲżŌĄŁżĄżņżŲżżżļ), 20160127.
- Product Brief, "Myriad 2 Vision Processor", Myriad2ż╬▄ć═ū╗┼══, 2014ŃQ7ĘŅ.
- Movidius╝ęż╬HP, "Embedded Neural Network Compute Framework: Fathom", Fathomż¬żĶżėFathom USB StickŠ╩¾, Movidius╝ę, 2016ŃQ.
- TechCrunch Japan(Ų³╦▄Ėņ)┼┼╗ęŠ╩¾, "MovidiusĪó║Ż┼┘żŽFathomż“╚»╔Į-ż╔ż¾ż╩źŪźąźżź╣żŌUSBź╣źŲźŻź├ź»żŪź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż¼ŠW(w©Żng)├ō▓─ē”", Fathom, Movidius╝ę, 2016ŃQ4ĘŅ29Ų³.
- Movidius╝ęź█Ī╝źÓź┌Ī╝źĖDJI, "DJI Unveils Mavic Pro Drone, Powered by Movidius", MA2155ż“DJI Droneż╦╗╚├ōĪó2016ŃQ9ĘŅ27Ų³.
- Movidius╝ęź█Ī╝źÓź┌Ī╝źĖ, "Movidius + Intel = Vision for the Future of Autonomous Devices", VPUĪ▄Intel RealSense, 20160905.
- Mike Demler, "Mobileye Increases Car EyeQ Computer-Vision Processors Will Enable Autonomous Vehicles", Microprocessor Report Insight Analysis of Processor Technologies, Mobileye, EyeQ4, 20150720.
- Press Release Details, "The Road to Full Autonomous Driving: Mobileye and STMicroelectronics to Develop EyeQ(R)5 System-on-Chip, Targeting Sensor Fusion Central Computer for Autonomous Vehicles", Mobileye, EyeQ5, 20160517.
- Nervana╝ęż╬ź█Ī╝źÓź┌Ī╝źĖ, "NERVANA HAS JOINED INTEL", Nervana╝ęĪóIntel╣ń±éĪó20160823(╣ń±é).
- Synopsys╝ęź█Ī╝źÓź┌Ī╝źĖ, "DesignWare EV5x Vision Processors", EV5źĘźĻĪ╝ź║, Synopsys, 2015ŃQ3ĘŅ.
- Synopsys╝ęWeb, "Design Ware EV6x Embedded Vision Processors", żŌżĘż»żŽhttp://www.synopsys.com/Japan/press-releases/Pages/20160601.aspx EV6źĘźĻĪ╝ź║Īó20160602.
- Jaehyeong Sim; Jun-Seok Park; Minhye Kim; Dongmyung Bae; Yeongjae Choi; Lee-Sup Kim, "A 1.42TOPS/W deep convolutional neural network recognition processor for intelligent IoE systems", 2016 IEEE International Solid-State Circuits Conference (ISSCC), Pages: 264 - 265, IoE, KAIST, 20160131.
- Abigail See, Minh-Thang Luong, and Christopher D. Manning, "Compression of Neural Machine Translation Models via Pruning", StanfordĮj, NMT (Neural Machine Translation)żžż╬Pruning┼¼├ō, 20160629.
- Abigail See, "CS224N Final Project: Exploiting the Redundancy in Neural Machine Translation", StanfordĮj, NMT (Neural Machine Translation)żžż╬Pruning║ŪĮķż╬źóźūźĻź▒Ī╝źĘźńź¾żžż╬┼¼├ō, 2015ŃQ10ĘŅ║ó.
- Danny Shapiro, "Automotive Innovators Motoring to NVIDIA DRIVE", NVIDIA Official Blog, NVIDIA DRIVE PX2, 20160104(CES).
- Wikipedia Multilayer perceptron (MLP)
- Geoffrey Hinton, A Practical Guide to Training Restricted Boltzmann Machines, ź╚źĒź¾ź╚Įj│žż╬ČĄ║Ó, RBM, 20100802.
- Ruslan Salakhutdinov, Geoffrey Hinton, "An Efficient Learning Procedure for Deep Boltzmann Machines", Neural Computation 24, 1967-2006 (2012), RBM, 2006ŃQ8ĘŅ24Ų³.
- Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh, "A fast learning algorithm for deep belief nets", Journal Neural Computation archive, Volume 18 Issue 7, July 2006, Pages 1527 - 1554 MIT Press, DBN, 2017ŃQ7ĘŅ.
- Geoffrey E. Hinton; Ruslan R. Salakhutdinov, "Reducing the Dimensionality of Data with Neural Networks". Science 313 (5786): 504-507, Auto Encoder, 20060728.
- Honglak Lee, Roger Grosse, Rajesh Ranganath, Andrew Y. Ng, "Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations", Proceeding of the 26th Annual International Conference on Machine Learning ICML 2009, Pages 609-616, CDBN, 20090614.
- Zidong Du, Robert Fasthuber, Tianshi Chen, Paoio Ienne, Ling Li, Tao Luo, Xiaobing Feng, Yunji Chen, Olivier Temam, "ShiDianNao: Shifting Vision Processing Closer to the Sensor", CAS, University of CAS, EPFL, InriaĪ╩źšźķź¾ź╣╣±╬®Š╩¾│žśOŲ░öUĖµĖ”ē|ĮĻĪ╦, The 42nd International Symposium on Computer Architecture (ISCA42/2015Ī╦, ShiDianNao, 2015ŃQ6ĘŅ13Ų³.
- Bernard Bosi, Guy Bois, and Yvon Savaria, "Reconfigurable pipelined 2D convolvers for fast digital signal processing", IEEE Trans. on Very Large Scale Integration (VLSI) Systems, 1999 Sep ;vol. 7 (no. 3): page 299-308, ║Ų╣Į└«▓─ē”2Dż╬ź│ź¾ź▄źļźą-.
- Vinayak Gokhale, Jonghoon Jin, Aysegul Dundar, Berin Martini, and Eugenio Culurciello, "A 240 G-ops/s Mobile Coprocessor for Deep Neural Networks (Invited Paper)", Computer Vision and Pattern Recognition Workshops (CVPRW 2014), 23 June 2014, Teradeep/nn-X, 2014623.
- Paul A. Merolla, John Arthur, Rodrigo Alvarez-Icaza, Andrew S. Cassidy, Jun Sawada, Nabil Imam, Steven K. Esser, Myron D. Flickner, Dharmendra S. Modha, "A million spiking-neuron integrated circuit with a scalable communication network and interface", Science 8 August 2014: Vol. 345 no. 6197 pp. 668-673, ╗©╗’Scienceż╦║▄ż├ż┐IBM, TrueNorthĪó20140808.
- TrueNorthż╬▌ö’BČ\Įč½@╬┴, 2014ŃQ8ĘŅ8Ų³, http://www.sciencemag.org/content/suppl/2014/08/06/345.6197.668.DC1/Merolla.SM.rev1.pdf.
- Seong-Wook Park, Junyoung Park, Kyeongryeol Bong, Dongjoo Shin, Jinmook Lee, Sungpill Choi, Hoi-Jun Yoo, "An Energy-Efficient and Scalable Deep Learning/Inference Processor With Tetra-Parallel MIMD Architecture for Big Data Applications", IEEE Trans Biomedical Circuits Systems, vol.9, No.6 Dec 2015, PP.838-48, KAIST, DL/DI, ISSCC2015 4.6ż╬Full Paper╚Ū)Īó 2015ŃQ12ĘŅ9Ų³.
- Seongwook Park, Sungpill Choi, Jinmook Lee, Minseo Kim, Junyoung Park and Hoi-Jun Yoo, "A 126.1mW real-time natural UI/UX processor with embedded deep-learning core for low-power smart glasses Purchase", Solid-State Circuits Conference (ISSCC), 2016 IEEE International, 14.1, KAIST, UI/UX, 2016ŃQ1ĘŅ31Ų³.
- Norm Jouppi, "Google supercharges machine learning tasks with TPU custom chip", Google Cloud Platform Blog, May 18, 2016, Google, TPU, 2016ŃQ5ĘŅ18Ų³.

